 国家高新企业 | ISO9001认证
国家高新企业 | ISO9001认证 二级病原微生物安全实验室
二级病原微生物安全实验室- 联系电话:+13336028502
- +400-161-1580
- service@guheinfo.com
国家高新企业 | ISO9001认证 二级病原微生物安全实验室

谷禾健康

当谈到肠道菌群研究时,16S测序是一种常用的方法,它在了解微生物组成和多样性方面非常重要且实用。
16S rRNA是细菌和古细菌中的一个高度保守的基因片段,同时具有一定的变异性。通过对16S rRNA基因进行测序,可以确定微生物群落中存在的不同菌属和菌种,并评估它们的相对丰度。
针对肠道菌群16s测序概括起来可以了解以下内容:
揭示微生物组成:通过16S rRNA测序,可以获得关于肠道菌群中存在的不同菌属和菌种的信息。这有助于了解菌群的组成,包括有益菌、有害菌和其他微生物的相对丰度。
探索微生物多样性:16S rRNA测序可以评估微生物群落的多样性水平。通过分析不同样本中的菌群组成和多样性指标,可以比较不同个体、不同健康状态或不同治疗干预对微生物多样性的影响。
鉴定潜在病原菌:通过16S rRNA测序,可以鉴定肠道中存在的潜在病原菌。这有助于了解潜在的疾病风险,并为相关疾病的预防和治疗提供指导。
监测治疗效果:在临床研究中,通过定期进行16S rRNA测序,可以监测治疗干预对肠道菌群的影响。这有助于评估治疗效果,并为个体化治疗提供依据。
指导个体化营养干预:通过16S rRNA测序,可以了解个体的肠道菌群状态,进而指导个体化的营养干预。根据菌群组成和功能,可以制定相应的饮食方案,促进肠道健康和营养吸收。
以上总结了16s对于了解肠道菌群的重要价值,今天本文主要分享和介绍16s测序相关的定义和术语,以及菌群命名的规则等。
正确的说法是16S rRNA(不是16s rRNA或16s rDNA)。
16S rRNA 代表16S核糖体核糖核酸 (rRNA),其中S(Svedberg) 是测量单位(沉降率)。该rRNA是原核核糖体小亚基(SSU)以及线粒体和叶绿体的重要组成部分。
下图显示了16S rRNA(简称16S)如何参与原核核糖体。
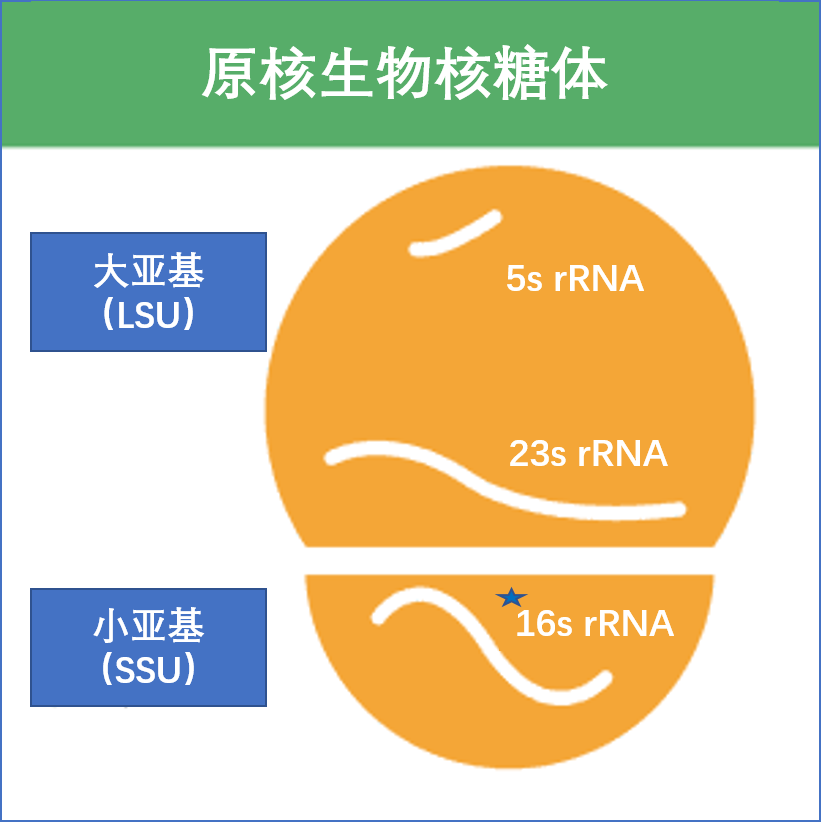
•16S rRNA在原核生物中发挥重要功能
16S rRNA是一种细菌和古细菌中常见的核糖体RNA分子。它在细胞中起着重要的功能,包括参与蛋白质合成的核糖体组装和识别启动子序列的功能。
由于16S rRNA在细菌和古细菌中具有高度保守的序列区域和变异的序列区域,因此它被广泛用于细菌分类和进化研究中。
相比之下,16S rDNA这个术语并不常用。rDNA是指编码核糖体RNA的DNA序列,因此16S rDNA可以理解为指代编码16S rRNA的DNA序列。
•科研中通常使用16S rRNA
在科研文献和学术讨论中,通常更常见地使用16S rRNA测序或16S ribosomal RNA测序。这种测序通常针对编码16S rRNA的DNA序列进行扩增测序,用来研究微生物的多样性和进化关系,特别是细菌和古细菌。
通过对16S rRNA基因进行测序,可以对微生物群落的组成和结构进行分析。这项技术在微生物学、生态学、医学和农业等领域有广泛的应用。
要用作DNA条形码,基因应具有以下特征:
•已知的细菌和古细菌都具有16S rRNA
它应该无处不在。否则,我们不能包括所有生物。已知细菌和古细菌的所有成员都具有16S基因。
它应该包含足够的系统发育信息。16S大约有1500bp长,不算太短也不算太长。
原核生物中发现的16S基因内的遗传变异足以用于广泛分类范围的系统发育分析。它成功地用于推断门之间的系统发育关系,同时也用于同一属的物种之间的比较。
•容易通过PCR扩增
它应该很容易通过PCR扩增。16S基因有多个保守区域可以作为引发位点。这成为基于NGS的短读长测序的一个显著优势。
经过多年的国内外研究和检测积累,我们拥有几乎所有已知细菌和古菌物种的16S序列数据库。通过在这些数据库中搜索16S序列,即使没有严格的分类学知识,也可以识别新分离的菌。
引物用于扩增
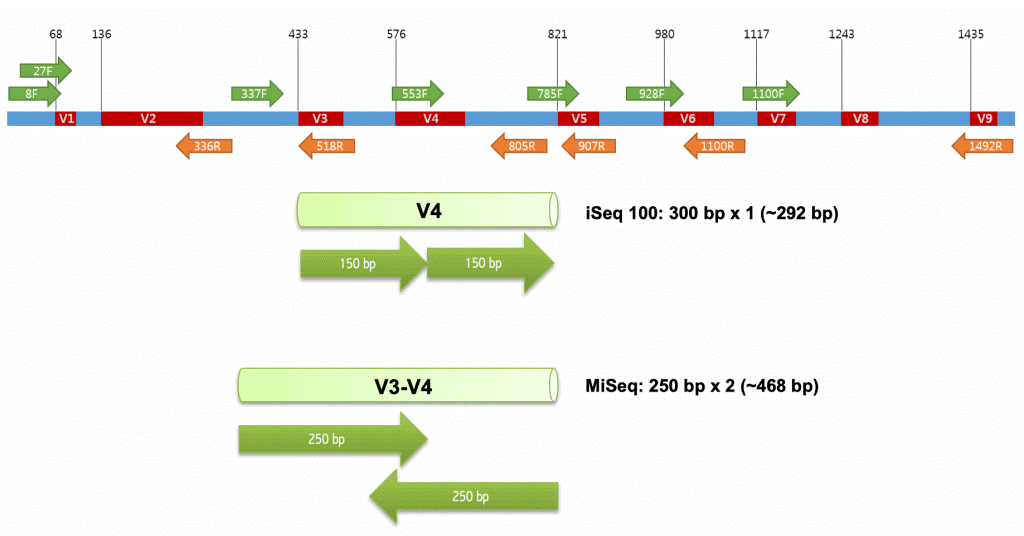
已知细菌16S之间的序列变异分布不均匀。在细菌中鉴定出9个高变区,分别命名为V1至V9。

从长度来看,全长16S长度为1.5kb左右,单菌落的16S全长sanger一代测序仍然是菌种鉴定的主要手段,纳米孔和Pacbio的三代测序可以高通量的获得全长序列,对于希望更高分辨率的分析菌种的研究有一定优势。
•三代测序建库成本较高,测序深度较低
三代的测序准确度目前逐渐改进,直接测序准确度可以在90%以上,纠错后可以提高到97~99%以上,已足够提供高精度的分类。三代目前主要问题在于建库成本相对较高,通过使用barcode可以降低部分但仍然偏高,此外普遍测序深度相对于二代测序要低许多。
•二代测序由于读长限制需要引物进行扩增
由于二代测序读长限制,无法使用高通量测序技术对16S rRNA整个基因全长进行测序,因此必须针对基因的某一片段设计引物进行扩增测序。
注:虽然有大量的文献研究不同片段的优缺点,但由于采用的样本类型、区域引物以及分析角度的不同,尚没有针对所有样本的最佳可变区片段的共识。
基于大量项目经验和文献调研, 目前最主要的可变区选择是V4区和V3V4区,V4区长度为256bp左右,加上两侧引物长度为290bp左右,使用双端2x250bp或2x150bp可以测通,此外如454、life、Illumina Hiseq 4000, Illumina Novaseq 6000的测序平台读长也可以主要涵盖该区段读长。
•16S V4 引物通用性是所有可变区中最高的
传统的认知中,普遍认为测序片段越长,测到物种数据就越多,故倾向选择16S V3V4。然而16S V4(515-806)引物通用性相对是所有可变区中最高的。且在大规模菌群调查研究中,如人体菌群研究HMP,地球微生物计划EMP,欧洲的FGFP、美国肠道计划AGP以及全球土壤菌群调查,都采用V4区作为检测区域。16S V4目前仍然是国际研究中使用最广泛和认可的检测区域。
细菌的命名法和命名受《国际原核生物命名法典》 (简称《原核生物法典》)的约束 ,但实际物种的分类则不然。例如,大肠杆菌(Escherichia coli)这个名称受《原核生物守则》的规范,但物种本身的特性和分类学分类不受规范。这意味着没有官方分类法,只有名称受到控制。
因此,“有效物种”、“正式物种”或“官方物种”等术语没有意义。只能验证名称,因此可以使用 “具有有效发布名称的物种”。
物种名称应由二项式系统的两部分组成:
(1)通用名称和(2)特定词缀。
如下示例:
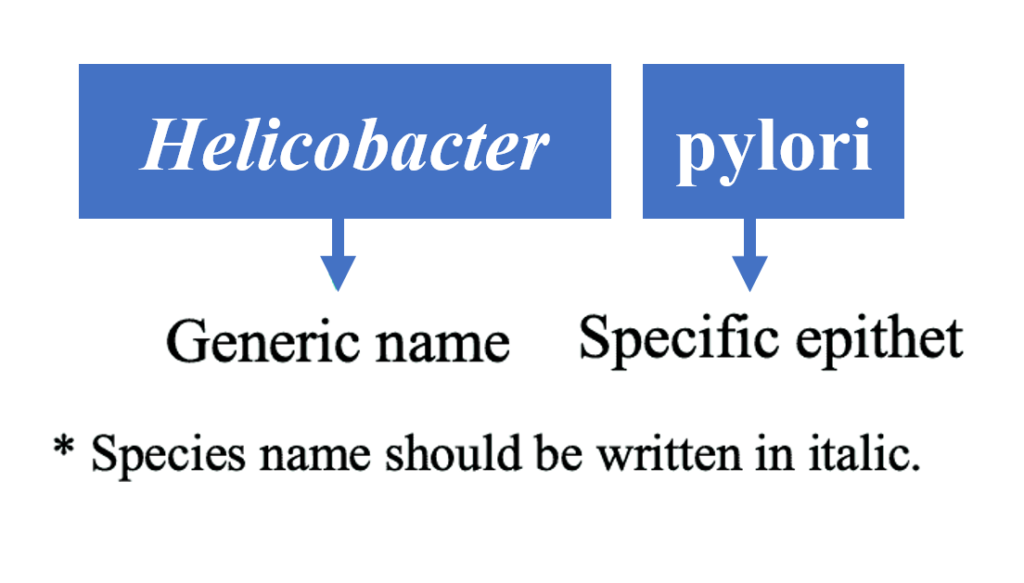
该组合代表“物种名称”,并且在命名系统中应该是唯一的。所有分类群的学名必须被视为拉丁文;物种等级以上的属群名称是单个词。
•生物分类按照不同等级
名称被组织成一个层次系统。
门(Phylum):门是细菌分类的最高级别之一,代表着细菌的大类别。细菌门包括了多个相关的纲和目。
纲(Class):纲是细菌分类的次级别,比门更具体。同一纲的细菌通常具有一些共同的特征和特性。
目(Order):目是细菌分类的更具体级别,比纲更详细。同一目的细菌通常具有更相似的形态、生理特征和生态习性。
科(Family):科是细菌分类的更具体级别,比目更详细。同一科的细菌通常具有更相似的基因组组成和代谢途径。
属(Genus):属是细菌分类的更具体级别,比科更详细。同一属的细菌通常具有相似的形态、生理特征和基因组组成。
种(Species):种是细菌分类的基本单位,代表着具有相似形态和生理特征的细菌群体。
亚种(Subspecies):亚种是种的更具体级别,用于进一步划分具有细微差异的细菌。
目前,门等级不受原核代码控制。提议将“门”纳入守则,但该提案尚未得到控制原核生物守则的机构国际原核生物系统学委员会(ICSP)的讨论和批准。
在细菌分类中,门、纲、目、科、属、种和亚种的命名规则和方法遵循国际细菌命名法。
以下是一些要注意的事项:
命名规则:细菌的命名应该是拉丁化的,以便在全球范围内使用和理解。通常使用斜体字体或以斜体书写。
门、纲、目、科、属、种和亚种的命名:这些分类级别的名称通常是基于拉丁词根、描述性词语、地名、科学家的名字或其他相关特征来命名的。例如,属名可以以科学家的姓氏命名,种名可以以形容词或名词来描述特定的特征。
•每个细菌分类级别的名称是唯一的
命名的唯一性:为了避免混淆,每个细菌分类级别的名称必须是唯一的。这意味着同一级别下的不同分类单元不能有相同的名称。
命名的正式发表:细菌分类的名称需要通过正式的科学出版物发表,以确保其被广泛认可和接受。这有助于维护分类的一致性和准确性。
命名的修订和更新:随着科学研究的进展和新的发现,细菌分类可能需要进行修订和更新。新的分类单元可能会被提出或已有的分类单元可能会被重新归类。这些修订和更新需要经过科学界的讨论和认可。
例如下面是假单胞菌菌名称和分类:
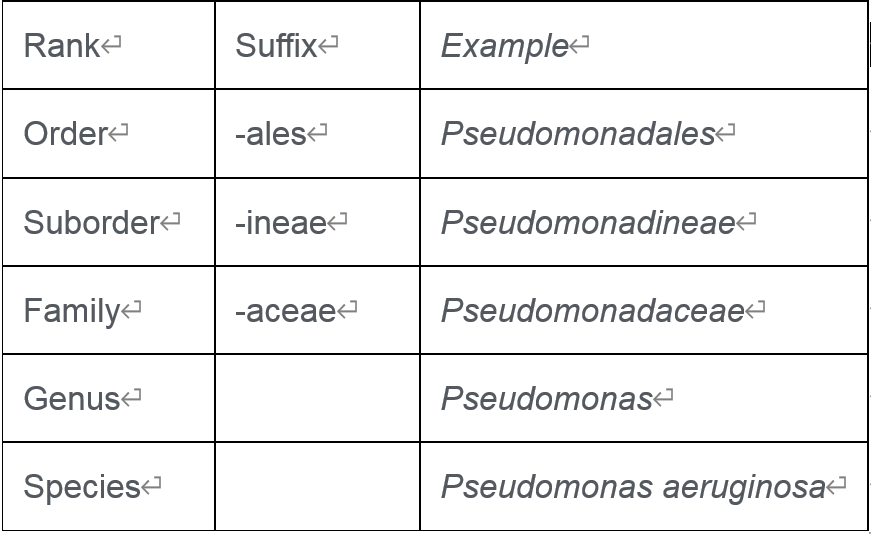
这些名称是由提出物种并将其分配给属的科学家给出的。例如, Thermacanus属已被提出,但并未将其归属于已知科。在NCBI分类学中,它属于芽孢杆菌目的暂定科“ Bacillales Family X. Incertae Sedis ” 。
EzBioCloud数据库将每个物种分配在完整的等级系统下,Thermicanus 被分配在暂定创建的家族“ Thermicanus_f ”下(请注意,这是一个无效名称,并且不是斜体)。当然,任何人都可以通过发表提案来提出Thermacanaceae家族的建议。
如前所述,名称由原核代码控制。要验证名称,该名称应包含在下述列表之一中。
▸ 批准的细菌名称列表
该论文由Skerman、McGowan 和 Sneath于1980年发表 ,标志着原核生物命名法的新开始。
此列表中的任何后续更改均由《国际系统与进化微生物学杂志》(IJSEM)(前身为《国际系统细菌学杂志》(IJSB))发布。
IJSEM中发布了两种类型的更新列表,即“通知列表”和“验证列表”。
▸ 通知列表
IJSEM是国际原核生物系统学委员会(ICSP)和国际微生物学会联盟(IUMS)细菌学和应用微生物学部的官方期刊。这意味着IJSEM是原核生物命名法的官方期刊。但是注意,没有官方的细菌分类法。
任何包含在IJSEM中发布的名称更改(新分类群或名称更改)的分类提案都将自动由IJSEM的列表编辑进行审核。如果论文符合《原核生物守则》的要求,则拟议的更改将被列入“通知列表”并被正式“验证”。
▸ 验证列表
原核代码还允许科学家有效验证在IJSEM以外的期刊上发表的名称。一旦名称被公布,就被称为“有效公布”。
任何关心科学的人都应该确保任何有效发布的名称都得到验证,方法是将出版物PDF发送给 IJSEM,并证明(对于物种和亚种)指定的类型菌株可以不受限制地从位于不同地区的至少两个公共培养物种保藏中心获得。
这可以由包括作者在内的任何人来完成。不这样做的带来的后果可能是有害的,因为该名称“有效发布”但从未“验证”。如果满足原核生物守则的所有要求(对于新物种和亚种,特别是规则27和30),IJSEM 的列表编辑将在验证列表中添加名称。
▸ 无效名称
不幸的是,在某些情况下名称无法验证。例如:
•一个名称在1980年之前被广泛使用,但在1980年没有被列入批准的细菌名称列表。
•一个名字在IJSEM之外发布,但从未被验证。
•没有人将PDF和进一步所需的文档发送给 IJSEM 进行验证。
•该出版物不符合准则的最低要求。
注:未有效公布的名称要用引号括起来,例如“Selenomonas Massiliensis”以区别于有效公布的名称。
•验证新物种的最低且唯一要求
根据原核生物守则, 验证新物种和亚种名称的最低且唯一的要求是:
•必须指定类型菌株。有时,描述新物种的论文不会提及哪个菌株是模式菌株。在这种情况下,名称无法验证。
•模式菌株应保藏于两个不同国家的两个培养物保藏中心。这确保了典型菌株仍然可用,例如当培养物保藏中心停止其活动或丢失菌株时。
•模式菌株必须通过培养物保藏中心可供任何人使用。专利菌株不能作为模式菌株。如果您想为某个菌株申请专利并限制其分布,则它不能作为物种或亚种的命名类型。
小结
以上总结起来如下:
确认命名规范:首先,确保您了解国际微生物学命名规范,如IJSEM是国际原核生物系统学委员会。这些规范包括命名原则、命名要求和规则,以确保新细菌名称的准确性和一致性。
检查已有命名:在确定您的新细菌名称之前,进行一次详细的文献调研,以确保该名称没有被其他研究人员使用或已经被正式命名。搜索相关数据库和文献,如国际细菌命名索引(International Journal of Systematic and Evolutionary Microbiology)和PubMed,以避免重复命名。
提交命名申请:一旦您确认您的新细菌名称符合命名规范并且尚未被使用,您可以准备提交命名申请。通常情况下,命名申请需要包括详细的描述、分类学特征、基因序列数据等相关信息。您可以向国际微生物学协会或相关的命名委员会(前面说的IJSEM)提交命名申请。
合作与审查:在提交命名申请之前,建议与其他研究人员、领域专家或命名委员会进行合作和讨论。这样确保命名申请符合规范。
审核和正式发布:一旦命名申请被提交,相关的命名委员会将对其进行审查。如果您的命名申请符合规范,经过审核后,新细菌名称将被正式发布,并被纳入相应的细菌命名索引和数据库中。
数据库很重要?
细菌名称的设计或命名是为了科学地组织,以提供基于系统发育的生物学见解;使用分层分类系统可以实现这一点。
•正确的名称对于解释微生物与其他数据的关联非常重要
例如,我们认为大肠杆菌与其他大肠杆菌物种比与芽孢杆菌物种有更多的表型特征。因此,使用正确的名称对于解释微生物组和其他类型的数据至关重要。
不幸的是,在当前的命名法中仍然有许多名称位于错误的位置。例如,Clostridium scindens因其在人类肠道菌群胆汁酸代谢中的重要作用而闻名,并且仍然保留着Clostridium的名称。然而,它甚至与梭状芽胞杆菌属并不接近 ,应归类为毛螺菌科的一个新属。
真正的梭菌属(Clostridium)属于梭菌科(Clostridiaceae)。例如Ruminococcus Sp(梭状芽胞杆菌)
梭状芽胞杆菌簇XIVa和IV 是已知在人类微生物组中发挥主要作用的细菌群。这些细菌簇在1994年才进入16S rRNA系统发育。
然而梭菌簇XIVa和IV 不代表正式命名法,也不表示单个分类群,例如属或科。自1994年以来,许多最初指定的属于梭状芽胞杆菌簇XIVa和IV的物种已被重新分类为新属。
•一些细菌存在错误的命名和分类
然而,这些簇中仍然存在错误分类的梭菌属物种,从而保留了旧名称。比如:Faecalibacterium prausnitzii(普拉梭菌),革兰氏阴性,对氧极度敏感,属于梭菌科,厚壁菌门。
该物种就是属于Clostridium clusterIV分组的Clostridium leptum group柔嫩梭菌类群,是该类群的最优势菌种。一般中文翻译柔嫩梭菌指的就是这个类群,其代表物种就是普氏栖粪杆菌,又名普拉梭菌。
以下是当前EzBioCloud数据库中对应于梭状芽胞杆菌簇XIVa和IV的分类群。
“Candidatus“是一个拉丁语词汇,通常用于微生物学中。它表示对一种微生物的命名,表示该微生物是一个新发现的候选物种,尚未被正式分类或命名。在中文中,”Candidatus“通常被翻译为”候选物种”或”候选菌种”。这个术语用于描述那些已经被发现但尚未被完全分类的微生物,通常是由于它们的特殊性质或难以培养。
总结来说,使用正确的细菌名称可以确保科学研究的准确性和一致性。细菌命名规范旨在为每个细菌物种提供唯一的、明确的名称,以避免混淆和误解。通过使用正确的名称,研究人员可以准确地标识和描述细菌物种,使得研究结果具有可比性,并促进科学交流和合作。
使用庞大的菌群的数据库,便于数据整合和共享。通过将新细菌与已知的细菌物种进行比对,可以确定其在分类学上的位置和相关信息。这有助于构建细菌分类树、建立物种间的关系,并为进一步的研究提供基础数据。
此外,正确的细菌命名和细菌样本数据库的比对可以促进研究进展和新的发现。通过对新细菌进行分类和命名,研究人员可以更好地理解细菌的多样性、生态学角色和潜在的应用价值。
人体肠道菌群健康检测需要依托本地化人群菌群样本检测的大数据库,区分菌群的组成和功能在个体间存在差异,并且与本地人体的生理状态、生化代谢、免疫炎症以及疾病风险等建立关联。通过建立大数据库,可以收集大量的菌群样本和相关数据,进行统计学分析和模式识别,从而揭示不同菌群组成与人体健康之间的关联。
总之,使用正确的细菌名称和拥有庞大的细菌样本数据库进行比对是确保科学研究准确性、促进数据整合和共享、推动研究进展和发现的关键步骤。
在某些情况下,即使一个物种是真实的并且具有科学重要性,也无法满足原核生物守则的基本要求。
根据正式命名法,这些物种的名字永远不会得到有效的公布。因此,分类学家创造了“Candidatus”一词来支持暂定命名。
对于Candidatus名称,没有纯培养物或分离株,因此没有典型菌株。由于Candidatus不属于正式命名法,因此不受原核法典管辖。
一个典型的例子是Candidatus Pelagibacter ubique该物种含有来自海洋的未培养或培养的细菌,可能是地球上最丰富的物种,因此它一定非常重要。
它从未得到验证的原因是该物种可以培养,但不能以培养物保藏所可用于长期储存的方式或规模进行培养。因此,无法满足该准则的最低要求。此外,特定的加词(ubique)格式错误。
并非所有Candidatus类群都得到了很好的表征,因为Candidatus的等级不受原核生物守则的规定。
•一般Candidatus的最低标准:
•提供全长高质量16S 序列,因为该基因是细菌和古细菌分类学的框架。
•未受污染且相当完整的基因组序列的可用性(通过域级核心基因的存在进行检查)。
•应提供最低限度的生态和代谢特征。
名称最好能代表该物种的典型特征。例如, Plasticicumulans这个名字的意思是“积累的塑料”。该属因积累生物塑料聚羟基脂肪酸酯而得名。
命名新分类单元的另一种流行方式是以人的名字命名。这个人应该有对科学做出贡献,尤其在微生物方面。著名的埃希氏菌(Escherich)和沙门氏菌(Salmon)是以微生物学家埃舍里奇(Theodor Escherich)和萨蒙(Salmon, D.E.)的名字命名的。
此外,以地理位置命名也很流行,但一般不鼓励。

谷禾健康

16S科研项目是一个完整的闭环,前期的课题项目设计方案、取样和重复实验设置决定了后期分析报告的数据完整性和项目类型。
想要拿到一手有利用价值的科研报告和项目数据,前期的实验方案设计和后续的分析都起着关键性的作用。
然而有时候拿到报告不知道如何去解读,这里为大家梳理一下16s科研项目的全过程,帮助大家更好的了解报告内容,快速获取关键信息。


实验方案设计就像一个总工程的设计图纸,决定了未来科研分析报告的类型走向,并且前期的分组设计的越详细,各种理化指标、生化指标、代谢物等信息准备越充分,后续报告的完整度越高。


明确项目课题类型
第一步要做的就是明确项目课题类型:
最常见的就是多分组之间差异分析比较:例如,要比较对照组、模型组、实验组,之间的差异结果。
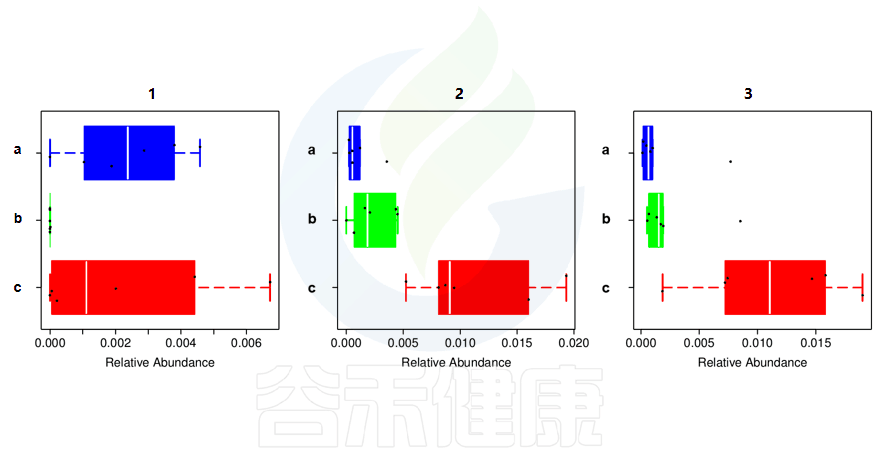

还有多分组中,任意两组之间比较:例如某实验设计了正常组、疾病组、用药组服用奥氮平、阿立哌唑、氨磺必利、利培酮,像比较不同的用药组和疾病组之间的菌群的差异结果,就用到了分组之间两两差异比较。
✦举个例子
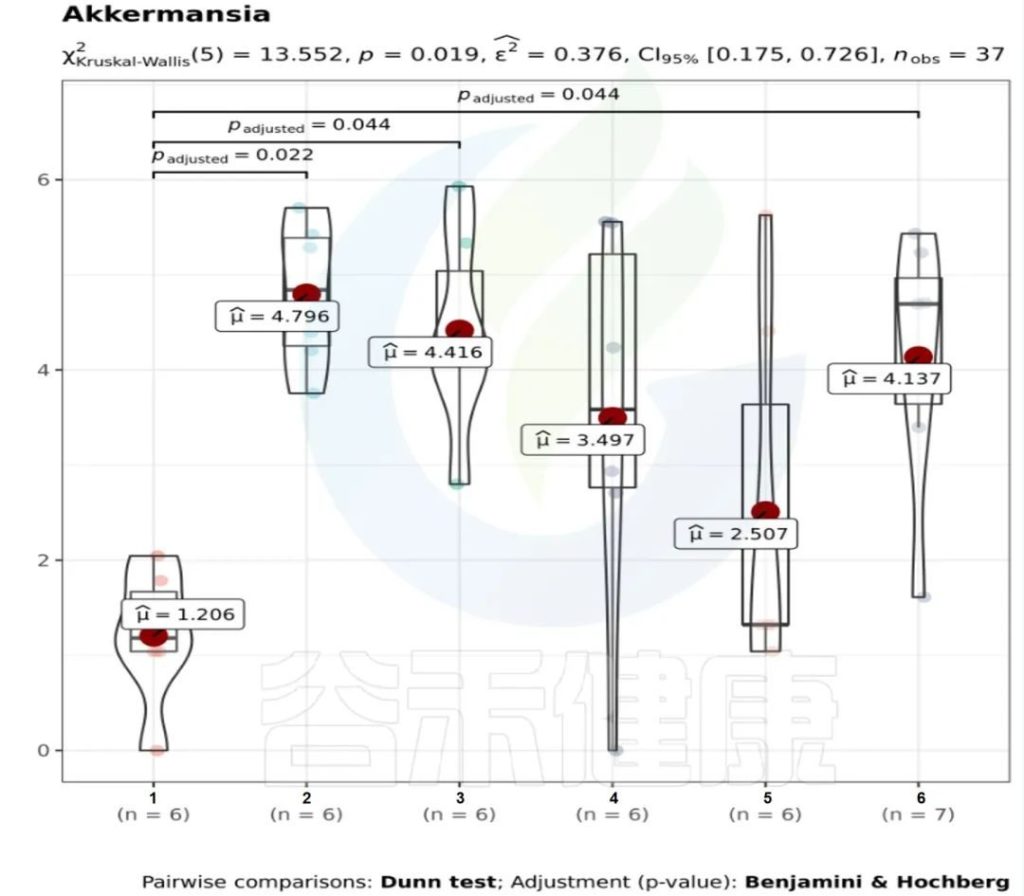
图中1组与3组、4组、6组 组间差异显著
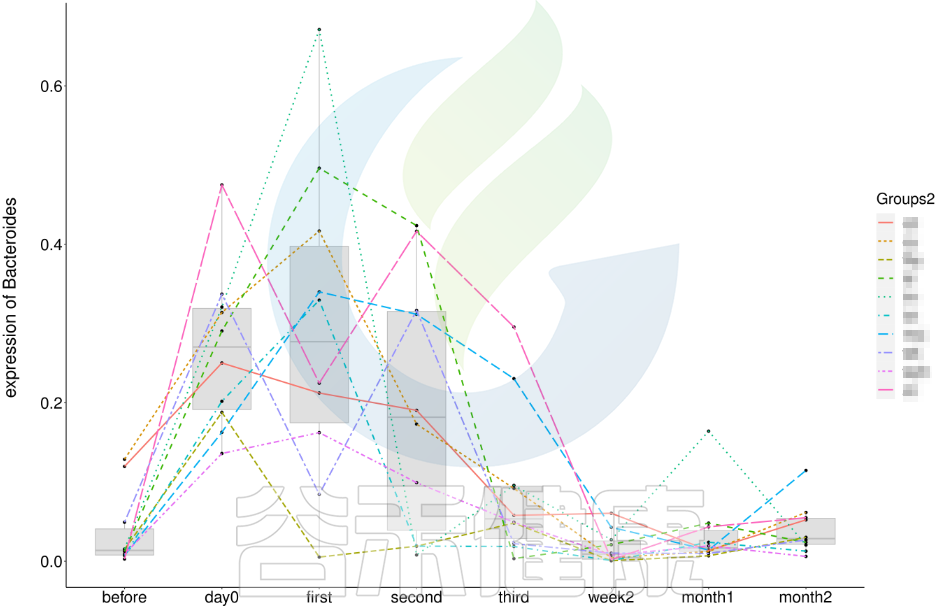
还有随时间的变化比较菌群之间的变化规律:例如在用药不同时间段包括3天,5天,2周,1个月,2个月,观察菌群的变化情况。如下图所示:
收集理化指标非常重要
如果前期搜集好每个样本的相关理化指标,还可以计算这些指标与菌群之间是否具有相关性。
✦举个例子
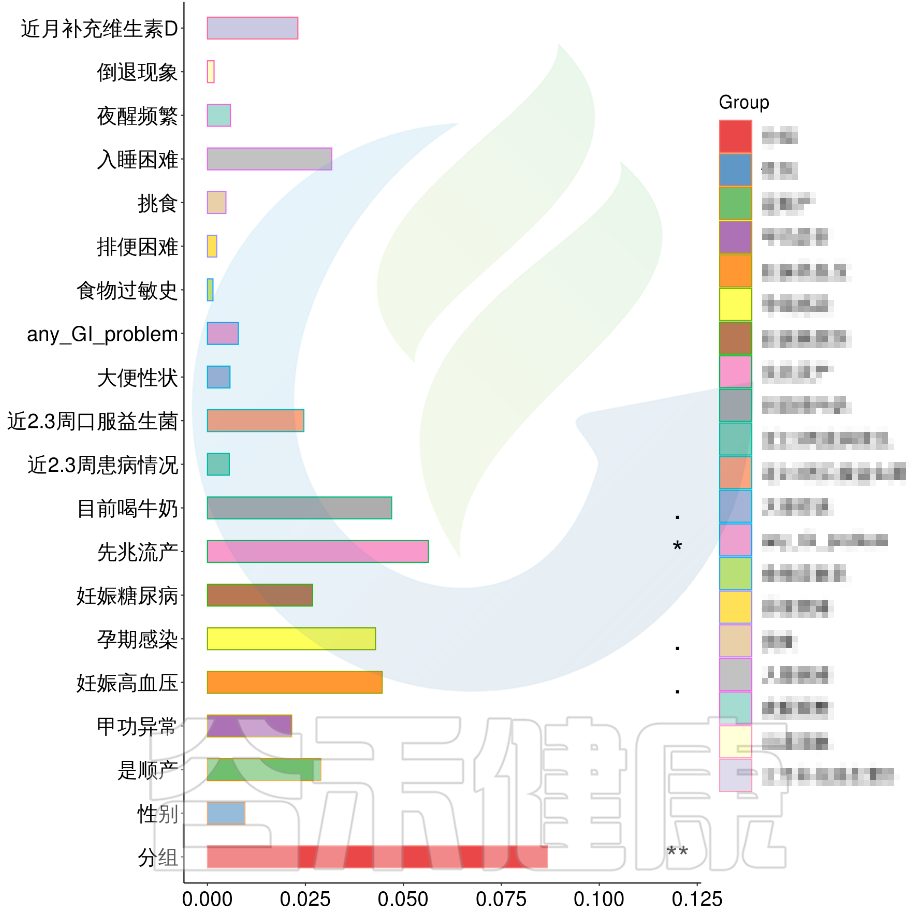
例如该项目比较自闭症儿童与正常儿童的菌群差异。客户在样本信息单里还详细搜集了母孕期的各种详细指标,例如孕期天数、出生体重、白细胞介素6、肿瘤坏死因子a、五羟色氨等数值型理化指标。
还搜集了是否顺产、是否妊娠高血压、是否孕期感染、是否妊娠糖尿病、是否先兆流产等因子型理化指标。其中0代表否,1代表是:
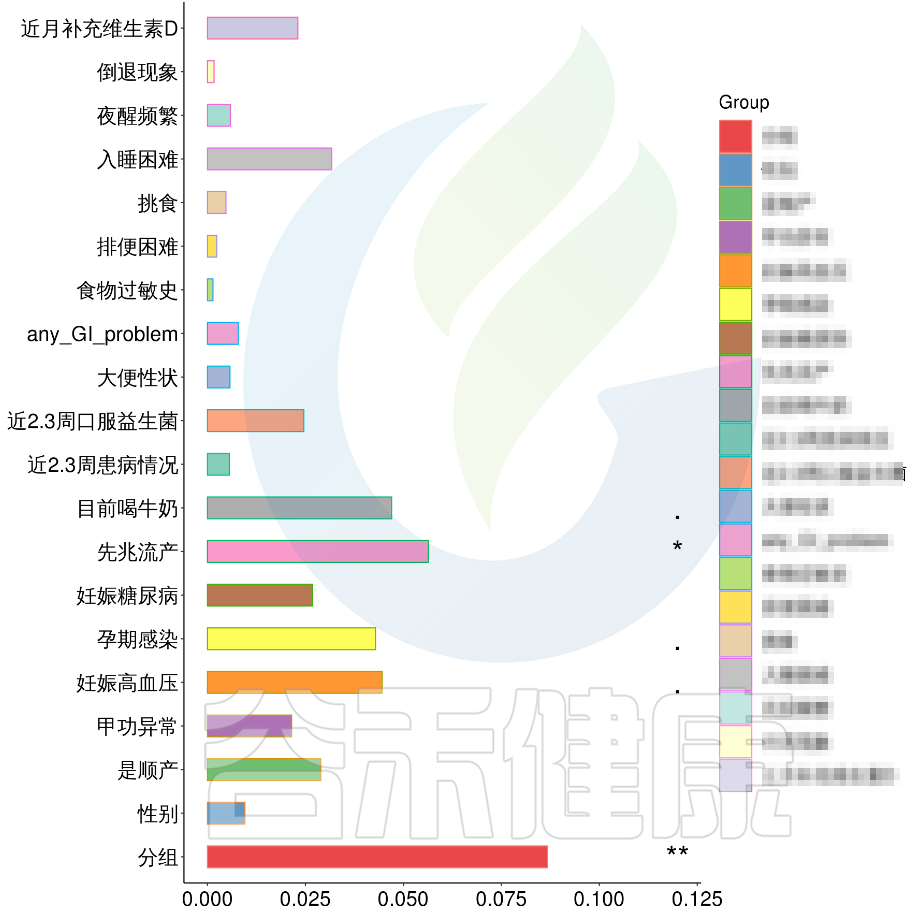
根据这些理化指标与菌群数据做相关性分析,从因子型的结果可以看出,自闭症(ASD)与正常儿童之间的分组与菌群之间相关性极显著**,其次是否有先兆流产的分组与菌群之间有显著相关性*,其他的包括是否喝牛奶、孕期是否感染、妊娠高血压都与菌群有相关性。
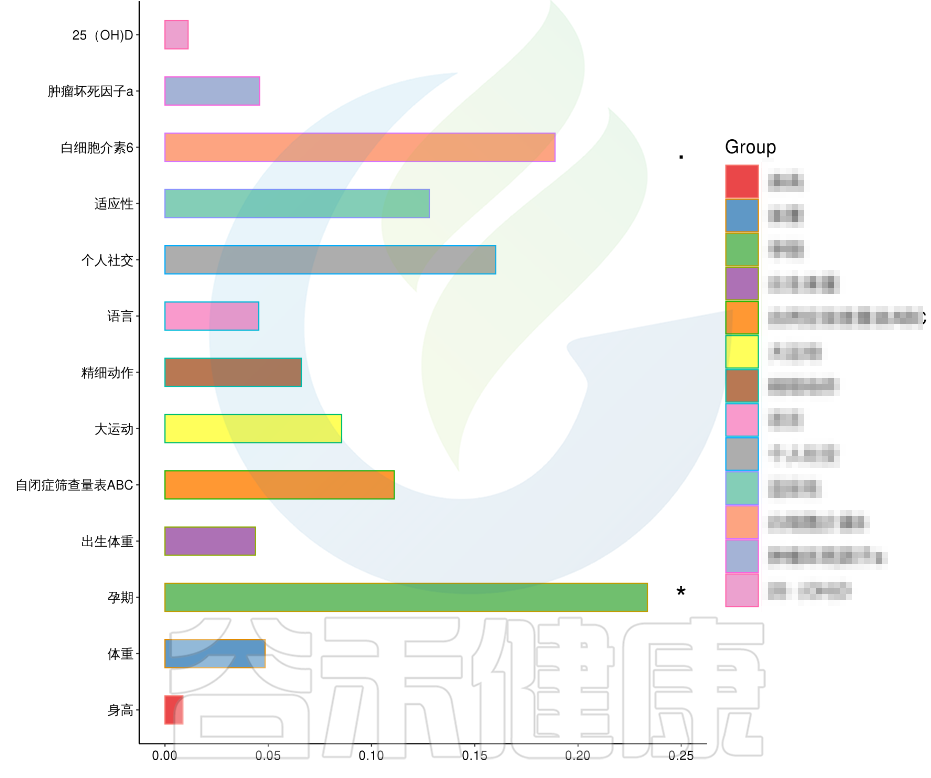
在数值型理化指标中,孕期的天数与菌群之间相关性显著*,其次是白细胞介素6与菌群之间有相关性。
小结
因此,前期搜集相关资料越详细充分,对分析报告的完整性也会有帮助,分析人员也会根据您的样本信息单提供的相关内容,做出个性化的分析和售后指导建议。
首先基于样本类型,最常见的环境样本来源是人体、动物、土壤、水体等。而人体中的肠道菌群样本是目前研究最广泛,可鉴定的物种也最为丰富,谷禾在肠道菌群与人体健康方面有深入研究,目前已完成超20万例临床肠道菌群样本检测,并构建了超过60万各类人群粪便样本数据库。
其他样本类型还包括人体/动物唾液样本、组织样本、尿液样本等。
▸ 粪便样本
目前粪便样本从采样到提取数据分析技术较为成熟、应用较为广泛,谷禾最早在15年就开发了针对粪便样本的取样管,也是最早致力于研发粪菌取样盒的公司,方便实验室、个人日常取样需求,实现了粪菌样本的常温运输。
谷禾取样管常温保存,取样也较为方便卫生,在家就可以轻松完成,相较于传统取样方法都有所升级。并且该取样管也有专利证书。该取样方法被大量客户采用并接纳,大大降低了采集粪便样本的难度,缩短了搜集样本的时间周期。
取样示意图

▸ 其他样本
土壤样本也相对较为容易提取出DNA,但需要注意的是土壤样本的菌群特征容易受植物腐殖质基因的影响和干扰,所以提取时要进行纯化。
而口腔、组织、尿液等样本,由于DNA含量较少,在实验阶段提取相对较为困难,所以提前准备样本时,尽量多取一些,并且可以多取几个重复,尽量避免扩增不出来的情况。
并且这些样还很容易受到环境样的污染,所以在实验阶段,可以取空白样本,和阳性样本ST做对照,数据分析时可以用来纯化样本,排除来自环境的干扰序列。
✦组间差异分析需重复取样
要做组间差异分析时,每组要重复取样,才能做组与组之间的统计检验。理论上,每个组至少3个样就满足基本的统计差异分析需求。所以在重复取样时,每个分组至少取3个样。取样时要保证每个分组内部的样本一致性,如果组内样本之间的个体差异性较大,则会影响后期组间差异结果分析。
✦举个例子
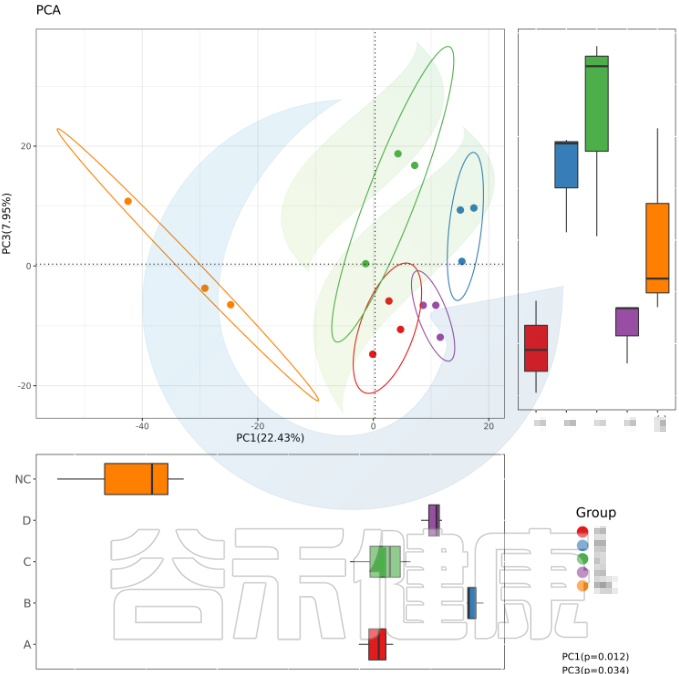
例如从该图可以看出,分组之间组间差异较大,并且组内的样本之间较为接近和相似。
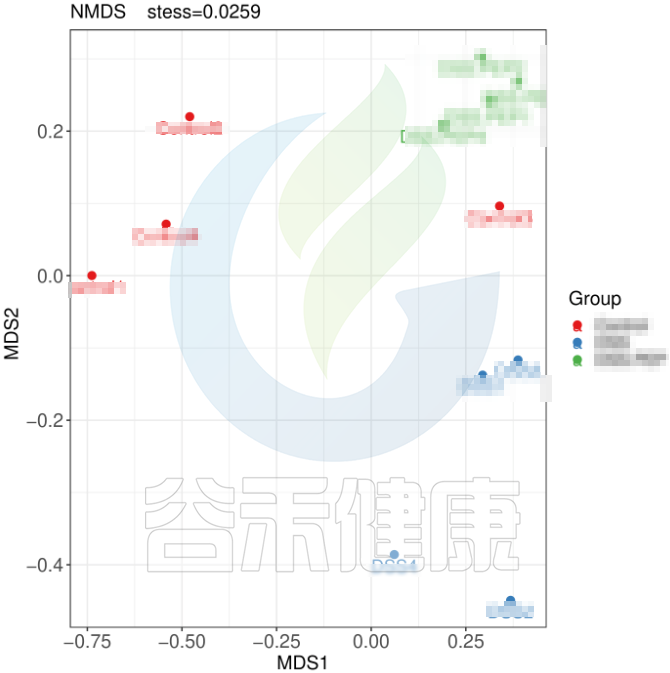
但从该图可以看出,Control组中Control3样本明显与组内的其他样本差异较大,与DSS组内的样本较为相近,这样就对后期组间差异分析的时候会产生影响,需要将该样本去除。
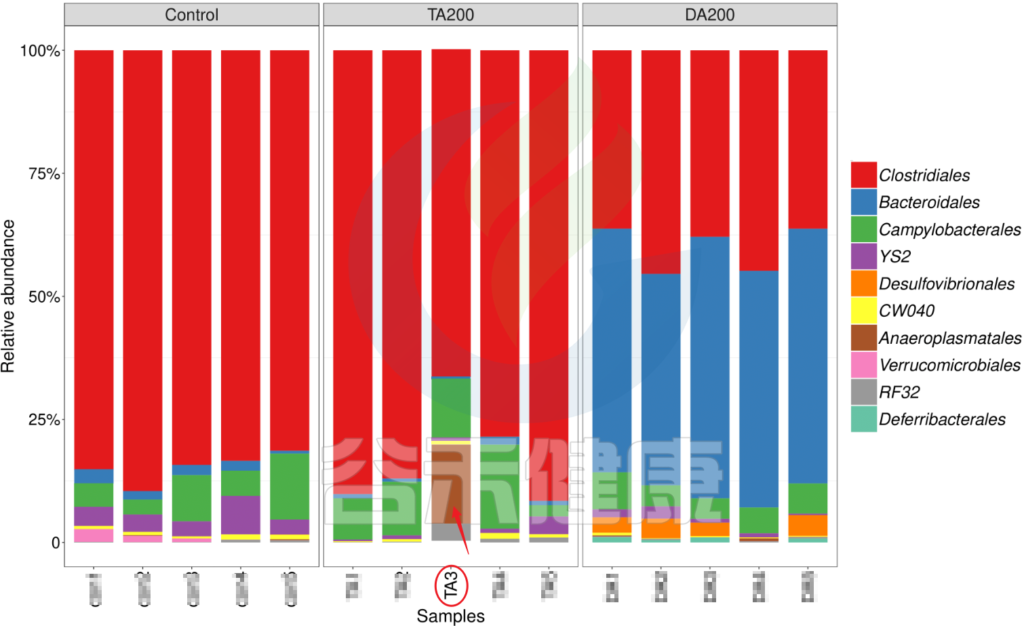
又例如在该图中,TA200组中的TA3样本的Anaeroplasmatales物种丰度含量非常高,该样本与组内的其他样本明显差异较大,该样本可能受到环境污染等其他因素干扰,这样就没有办法保证组内样本的均一性,也会影响分组之间的差异分析统计结果,再后期分析的时候建议把该样本去掉重新分析。
建议
为了便于后期数据整理修改,每个分组需要保留一定量的重复样本,假如每个分组只取了3次重复,假如其中有一个样本质量不好需要去除,该分组只剩2个样本,则不满足每组至少3个样的分组条件,整体就没有办法做组间差异分析统计。
所以这里建议每个分组至少取5个样做重复,一般6到10个样就能分析出比较完善的结果。具体分组和组内的重复取样数量视具体的实验设计方案而定。
在经费允许的情况下,建议多取一些重复。假设每组取50到100个重复或者以上,得到的分析结果就基本可以涵盖该分组情况所有的菌群构成情况,可以较为全面的研究分组之间的菌群构成差异情况。
当拿到16S科研分析报告以后,面对纷繁复杂,各式各样的图表分析结果犯了难,不知道如何从这么多的图表中入手,快速找到报告中需要的图表结果。
这里对16S科研分析结果抽丝剥茧,概括出报告中的主要几大内容板块。
•16S科研分析究竟是在做什么?
16S rDNA 是一种对特定环境样品中所有的细菌进行高通量测序,以研究环境样品中微生物群体的组成,解读微生物群体的多样性、丰富度及群体结构,探究微生物与环境或宿主之间的关系的技术。
主要是对原始数据进行拼接过滤得到的优化序列,降噪方法得到ASV,再对ASV进行物种注释,注释到门、纲、目、科、属、种各层次上的分类结果。
通过ASV表计算Alpha多样性,样本内的多样性指数,Beta多样性,样本间相似性的指标。
对ASV表进行功能预测,例如Picrust2功能预测分析、Bugbase菌群表型特征分析,FAPROTAX生态功能预测等。
得到的每个样的数据结果,根据客户提供的分组情况和理化指标,进一步做组间差异分析,以及和环境理化指标之间做关联分析,相关性分析,比较分组之间是否有差异,差异是否显著,来验证分组是否合理,和环境宿主之间是否有关联性。
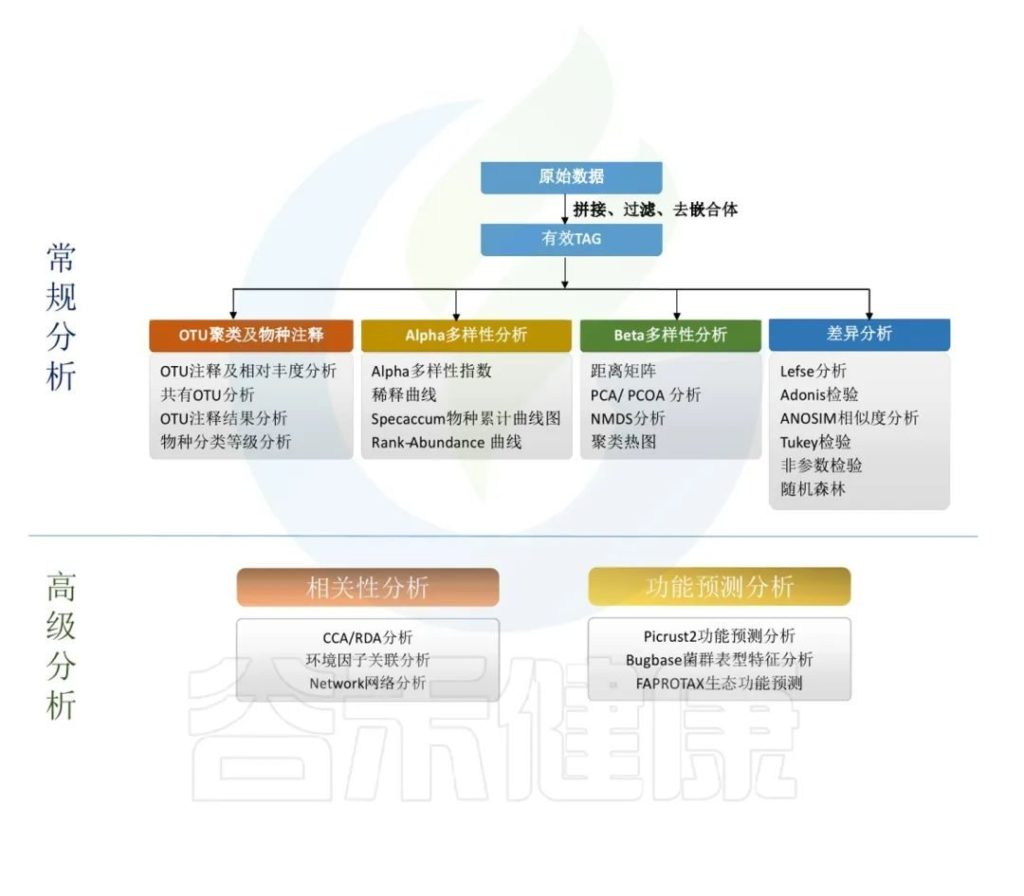
原始数据处理
Illumina NovaSeq测序平台测序得到的双端数据Raw PE,经过拼接和质控,根据一定的标准过滤掉低质量数据、接头或PCR错误,得到Raw Tags。再经过去重复序列,去singleton序列,过滤嵌合体,得到可用于后续分析的有效数据 Effective Tags。
OTU(ASV) 表生成
微生物多样性分析中最重要的就是OTU特征表,一切后续分析都围绕OTU表来进行。生成OTU除了传统的聚类的方法(一般按照97%的相似度进行聚类),现在最新用到的技术的是降噪的方法得到ASV。
简单来讲ASV就是在去除了错误序列之后,将Identity的标准设为100%进行聚类,常见的有DADA2、Deblur、Unoise三种降噪方法。项目里用到的是UNOISE2降噪方法获得ASV数据。
物种的分类与注释
采用QIIME2训练分类器方法对ASVs代表序列进行分类学注释,默认选用SILVA138数据库进行物种注释。并在各个分类水平上:domain(域),phylum(门),class(纲),order (目),family(科),genus(属),species(种)对每个样本的群落组成统计。
alpha多样性
Alpha多样性主要反映样本内多样性。对ASV表进行计算可以获得每个样本的simpson,ace,shannon,chao1以及goods_coverage等指数,alpha多样性指数用来来评估样本菌群物种的丰富度(richness)和多样性(diversity)
beta多样性
Beta多样性反映的是样本间多样性,Beta多样性是衡量个体间微生物组成相似性的一个指标。通过计算样本间距离可以获得β多样性矩阵,基于OTU的群落比较方法报告中给出了,欧式距离、bray curtis距离、Unweighted UniFrac距离和Weighted UniFrac距离等。
功能预测
得到群落的微生物组成之后,也可以对群落功能组成进行预测,常用的16S功能预测的相关软件有PICRUSt2、FAPROTAX、BugBase。
PICRUSt2用来预测功能,通常指的是基因家族,PICRUSt2支持基于多个基因家族数据库的预测,报告中包括了KEGG同源基因,KO直系同源物,EC酶分类编号,MetaCyc途径的丰度,CAZy碳水化合物活性酶数据库,GMM是肠道代谢模块和GBM是肠脑模块。
FAPROTAX是原核的微生物注释代谢或其他生态相关的功能(例如硝化,反硝化,发酵)的一个数据库和软件。FAPROTAX预测的功能主要集中在海洋、湖泊等环境样本微生物的功能,特别是硫、碳、氢、氮的循环功能。
BugBase能进行表型预测,其中表型类型包括革兰氏阳性(Gram Positive)、革兰氏阴性(Gram Negative)、生物膜形成(Biofilm Forming)、致病性(Pathogenic)、移动元件(Mobile Element Containing)、氧需求(Oxygen Utilizing,包括Aerobic、Anaerobic、facultatively anaerobic)及氧化胁迫耐受(Oxidative Stress Tolerant)等7类。
以上这些部分,我们通过数据处理分析,得到了每个样本相关的大量数据结果,包括每个样本的序列统计、ASVs表格、物种分类注释统计、alpha多样性指数、beta多样性指数、功能预测等。这些数据主要集中在报告里的这些内容:
▸ 科研分析报告结果文件夹
01_pick_otu/ 文件夹主要是对样本ASV表格统计
02_sequence_statistic/ 文件夹是对样本序列数据的统计
03_diversity-metrics / 文件夹是对样本的alpha多样性指数、beta多样性指数的统计
04_Taxonomic/ 文件夹是对物种分类注释的统计(门到种水平)
Picurst2/ 文件夹是Picrust2功能预测得到的每个样本的相关功能预测数据
Groups/ 文件夹下是对组间差异分析结果

红框是样本个体的相关数据统计,Group是分组比较
根据以上常规分析得到的相关数据进行作图,其路径也在对应文件夹下,可以打开 分析报告.html 有相关分析的图表和对应文件的详细介绍和路径说明。
★拿到样本后需要进行统计分析
当我们拿到这些样本大量的数据结果,之后关键的一步就是做对这些数据进行处理,做统计分析,比较分组之间的差异结果,找出菌群和环境之间的关联性等,对数据进一步做研究,找出课题方案对应的结果。
不同的数据用到的统计检验方法也不太一样,接下来我们对报告中的不同的分析结果对应的统计差异分析方法进行介绍说明。
▸ alpha多样性
alpha多样性指数组间差异统计分析用到的检验方法是:单因素方差分析(如果只有两个分组,用Wilcoxon秩和检验,3个及以上的分组用Kruskal-Wallis 检验),图上方显示P值
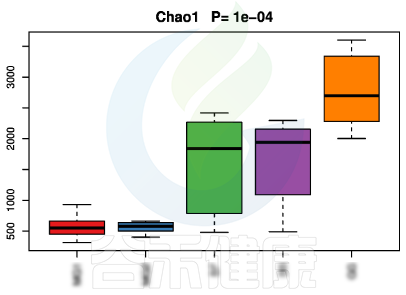
▸ beta多样性
beta多样性指数的统计检验方法有ANOSIM相似性分析和Adonis多元方差分析,这两种都是基于距离矩阵的检验方法。
✦Anosim相似性分析
Anosim分析是一种非参数检验,用来检验组间的差异是否显著大于组内差异,从而判断分组是否有意义。
报告中给出了加权距离和非加权距离的Anosim结果图,图中给出了R值和P值。
R值用于比较不同组间是否存在差异,R-value 介于(-1,1)之间,R-value > 0,说明组间差异大于组内差异。R-value < 0,说明组间差异小于组内差异。R只是组间是否有差异的数值表示,并不提供显著性说明。
统计分析的可信度用 P-value 表示,P< 0.05 表示统计具有显著性。
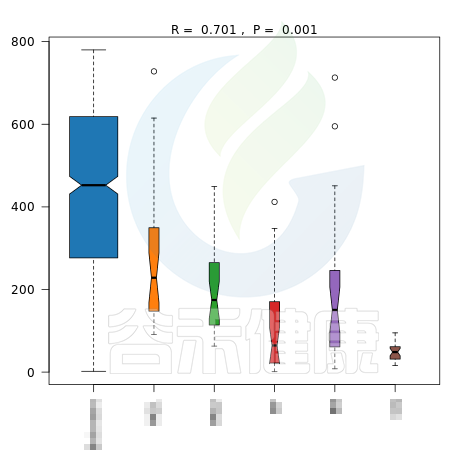
图中能看出R>0,说明组间差异大于组内差异,P<0.05 ,说明差异显著,证明该分组情况效果较好。
✦Adonis多元方差分析
Adonis多元方差分析,其实就是PERMANOVA,亦可称为非参数多元方差分析。
其原理是利用距离矩阵(比如基于Bray-Curtis距离、Euclidean距离)对总方差进行分解,分析不同分组因素对样品差异的解释度,并使用置换检验对其统计学意义进行显著性分析。
它与Anosim的用途相似,也能够给出不同分组因素对样品差异的解释度(R值)与分组显著性(P值)。
报告中PCoA bray距离、PCoA weighted_unifrac距离、PCoA unweighted_unifrac距离的图片右下角有给出PERMANOVA检验的P值和R值。
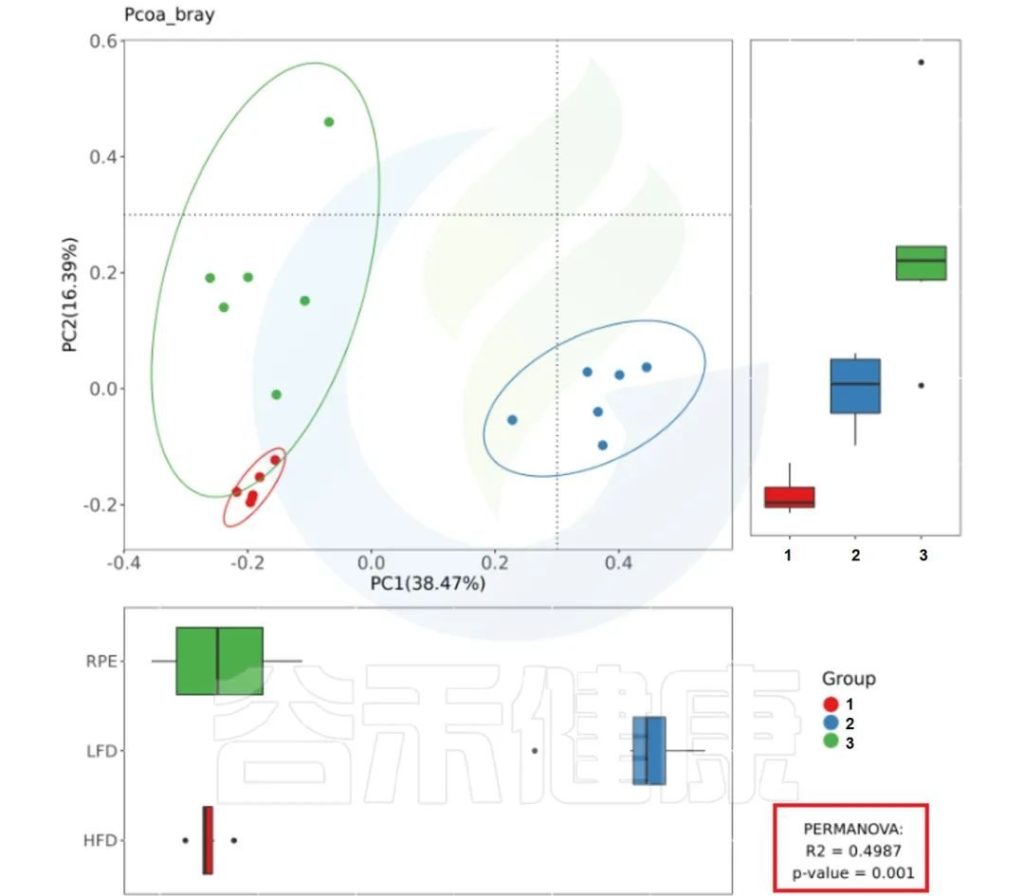
图中看出PCoa bray距离得到的检验P<0.05 组间差异显著,并且分组之间区分较为明显。
PCoa bray距离的PERMANOVA检验结果路径:
多组间检验结果:
Groups/betadiv/pcoa_bray_analysis/PERMANOVA.result_all.csv
两组间检验结果:
Groups/betadiv/pcoa_bray_analysis/ PERMANOVA_paired_result.csv

不同分类水平下的检验方法
在很多分析报告当中,例如在不同疾病的肠道菌群分组中,本身样本个体之间肠道菌群的物种多样性,丰富度差异并不大,alpha多样性组间差异并不显著,beta多样性分组间区分不是很明显,这样就需要进一步找出分组之间的差异物种或者差异功能来进行分析。
对于不同分类水平的物种和功能预测结果用到以下几种检验方法:
Tukey检验
Tukey主要应用于3组或以上的多重比较,适合于各组例数相等的每两两分组之间比较。
Tukey检验的一个重要的优点是非常简单,而且所需实验样本相对较少。
其检验结果的可信度达到95%的置信水平时,最少的情况下只需6个样本进行验证(改善前3个样本、改善后3个样本)。
•举个例子
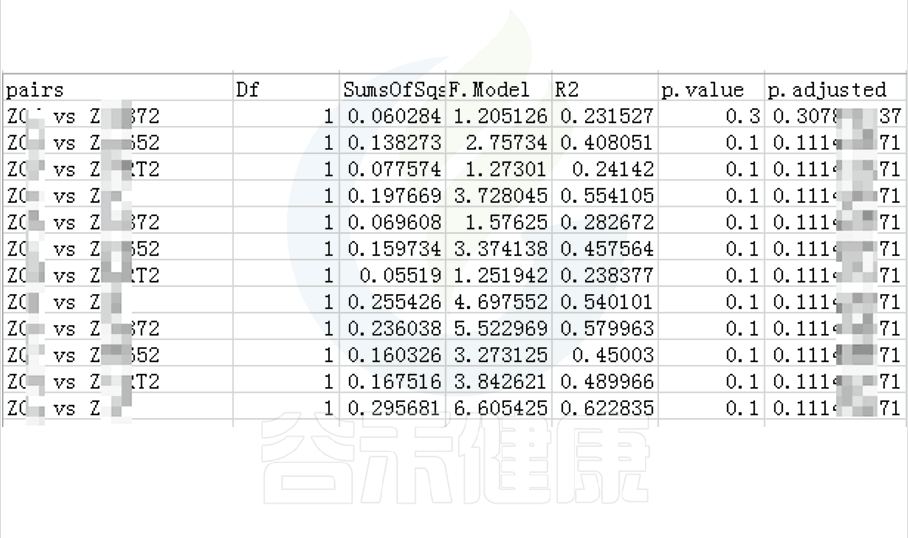
图中的字母代表显著性差异的字母表示法,只要含有相同的字母,就表明两组之间没有显著性差异。
例如a和ab含有相同字母“a”,表示两组之间没有显著性差异。ab中的“b”表示这一组和其他含有字母b的组(比如bc)没有显著性差异,但是a和bc就有显著性差异了。
图中只展示Tukey检验差异显著的物种或功能,如果数量较多,则只展示前10个。
路径:Groups/diff_analysis/TukeyHSD/
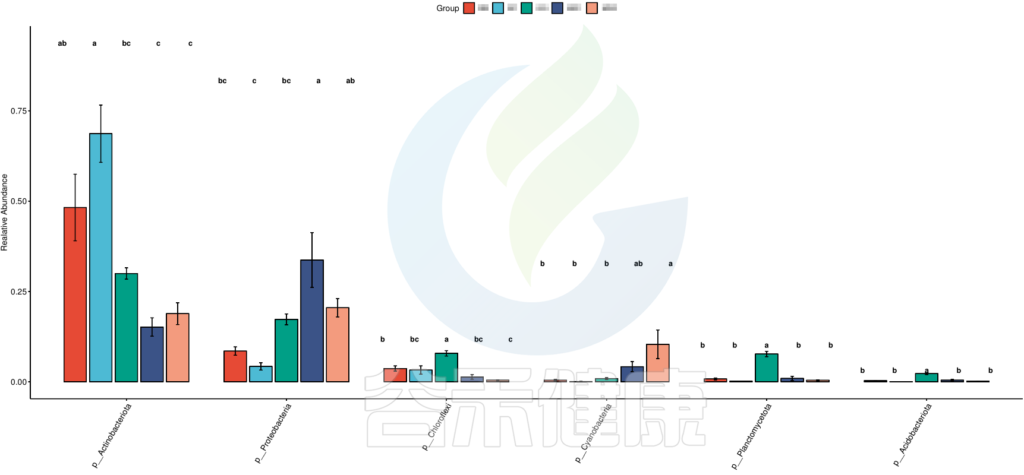
图中显示的都是Tukey检验组间差异显著的物种,依次按照丰度从高到底排列,如果差异结果较大,则显示前10个物种。例如在该图中,Tukey检验结果,门水平物种Actinobacteriota在BB与MG1组、BB与MG2、BF与GG组、BF与MG1组、BF与MG2组,这些分组之间组间差异显著。
组间差异箱型图
组间差异箱型图用到的检验方法是通过单因素方差检验(只有两个分组,用的是Wilcoxon秩和检验,3个及以上的分组用的是Kruskal-Wallis 检验),Var检验和one-way相结合,筛选出组间差异性物种。
路径:Groups/diff_analysis/TaxaMarkers
图中每一个箱型图代表一个组间差异显著的物种
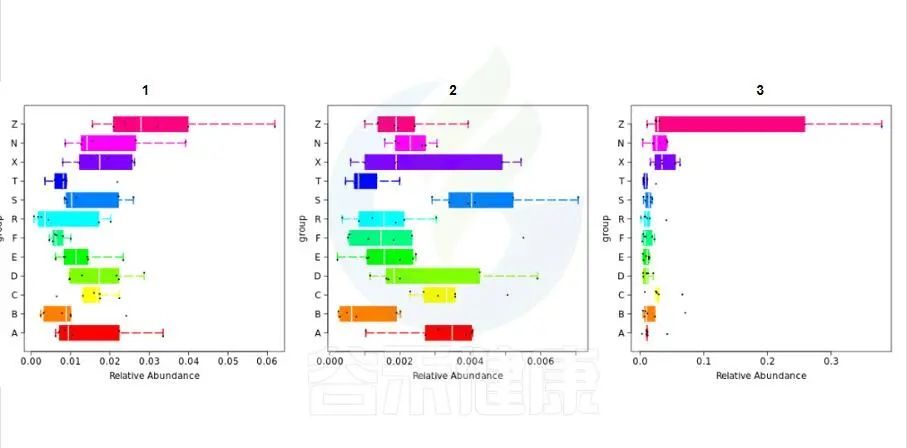
图中显示的都是统计方法得到的差异显著的物种,图中能看出这3个物种分组之间差异显著。
命名格式是,例如:Cen_Nitrosopumilus 指的是,当前分类水平(属水平)的名字 g__Nitrosopu 加上一级分类水平(科水平)的名字 f__Cenarchaeaceae 的前 3 个字母简写Cen,如果当前水平没有注释到名字则以全称的名字表示。
统计结果表:Groups/diff_analysis/TaxaMarkers/ xxx.Groups.sig.meanTests.csv
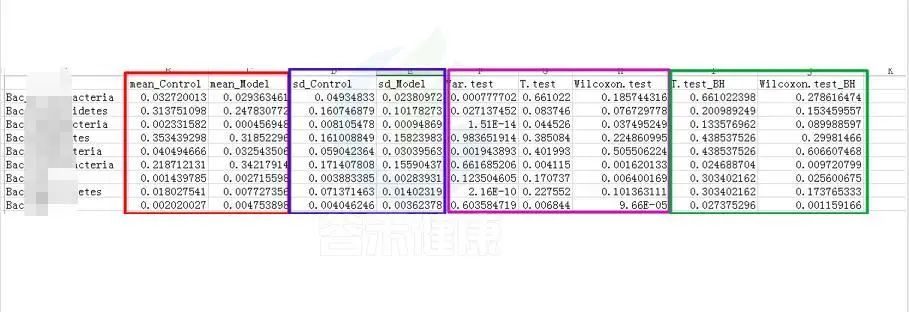
例如这是一个表格的截图
红框 mean_ 是分组组间的平均值
蓝框 sd_ 代表组间的标准差
粉色 .test 代表不同统计检验结果的P-value P值,这里有var检验 T 检验 Wilcoxon检验(或Kruskal-Wallis 检验)
绿色 _BH 例如Wilcoxon.test_BH代表Wilcoxon.test检验BH矫正的Q-value,Q值
UnivarTest检验(单因素方差分析)
单因素方差分析是指如果只有两个分组,用Wilcoxon秩和检验,3个及以上的分组用Kruskal-Wallis 检验。
路径:Groups/diff_analysis/UnivarTestXXX
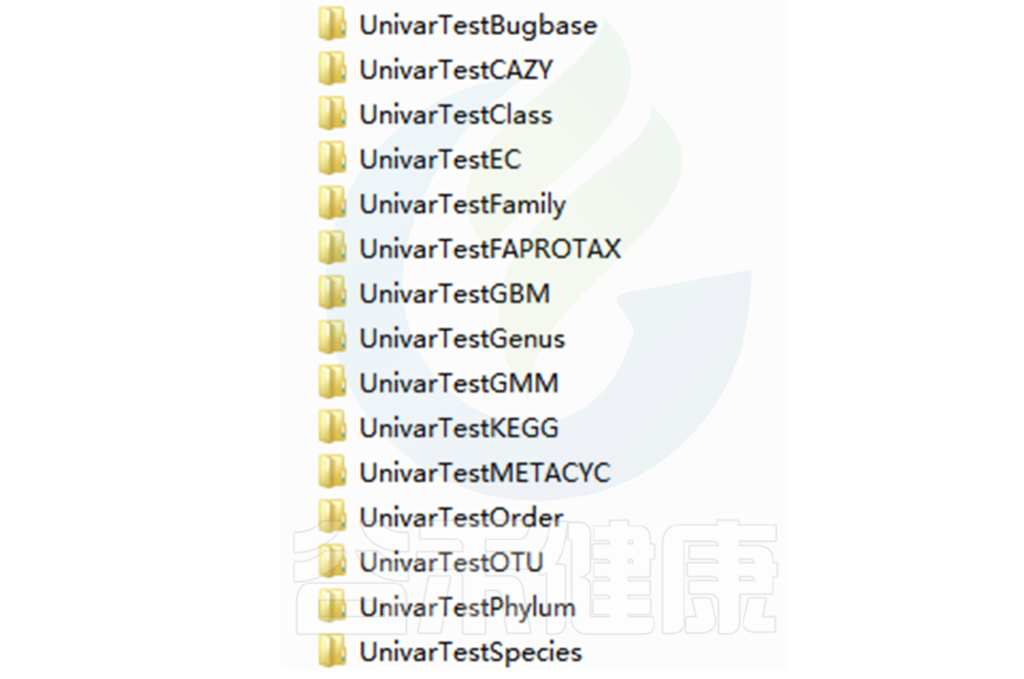
Groups\diff_analysis\UnivarTestKEGG\figure 文件夹下有做成柱状图、箱型图和单个物种之间的图,其中有横着排列和竖着排列的,有用原始值计算的,还有对原始值取log后进行统计的。图中只展示Univar 检验组间差异显著的物种/功能。
统计结果表:Groups/diff_analysis/UnivarTestXXX/ UnivarTest_sign.txt
•举个例子
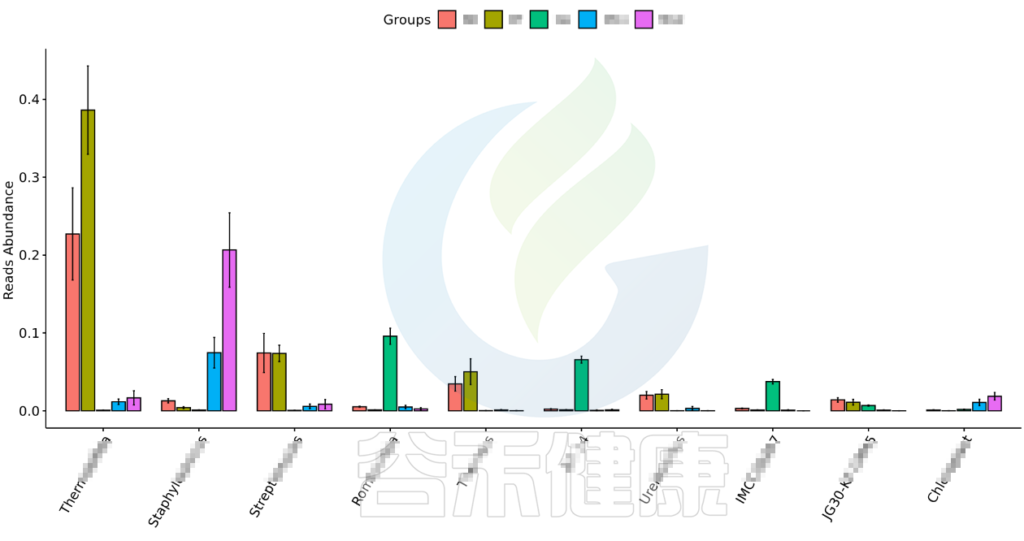
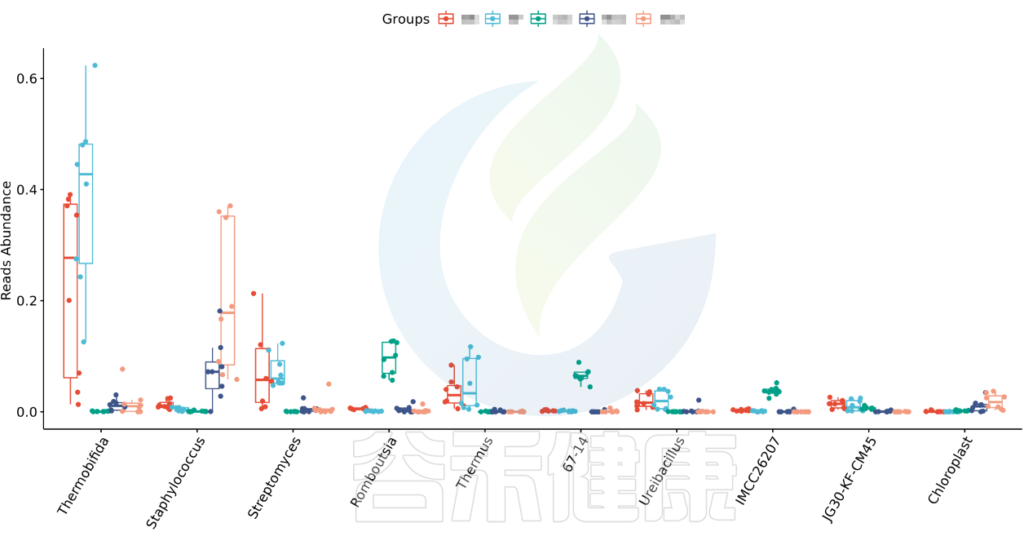
图中显示的是该统计检验差异显著的物种的柱状图或箱型图,按照丰度从高到低排列,如果差异物种/功能较大,则只显示前10个。例如该图中Therobifida、Staphylococcus、Streptomyces等物种用Kruskal-Wallis 检验得到的组间显著差异物种。
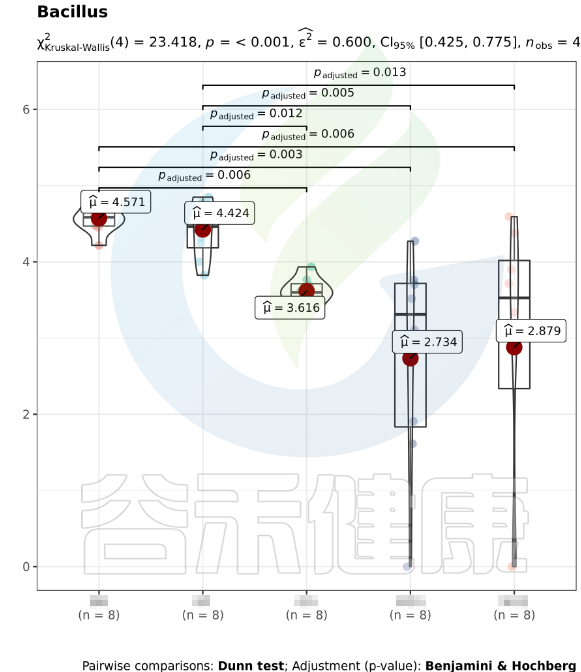
该图展示了Bacillus物种Kruskal-Wallis 检验差异结果,所有分组中P<0,001 多组间差异显著,两组间BB与GG、BB与MG1、BB与MG2、BF与GG、BF与MG1、BF与MG2,组间差异显著。
LEfse分析
LEfse分析即LDA Effect Size分析,是一种用于发现和解释高维度数据生物标识(基因、通路和分类单元等)的分析工具,可以进行两个或多个分组的比较,它强调统计意义和生物相关性,能够在组与组之间寻找具有统计学差异的生物标识(Biomarker)。
LEfSe用到的统计分析方法是将线性判别分析与非参数的Kruskal-Wallis以及Wilcoxon秩和检验相结合。
LEfse分析结果中一般会出现两个图,一张表( LDA值分布柱状图、进化分支图以及特征表)。
LDA值分布柱状图
这个条形图主要为我们展示了LDA score大于预设值的显著差异物种,即具有统计学差异的Biomaker,默认值为2.0(看横坐标,只有LDA值的绝对值大于2才会显示在图中);柱状图的颜色代表各自的分组,长短代表的是LDA score,即不同组间显著差异物种的影响程度。
路径:
Group/Lefse_Analysis/out_formant.cladogram.png
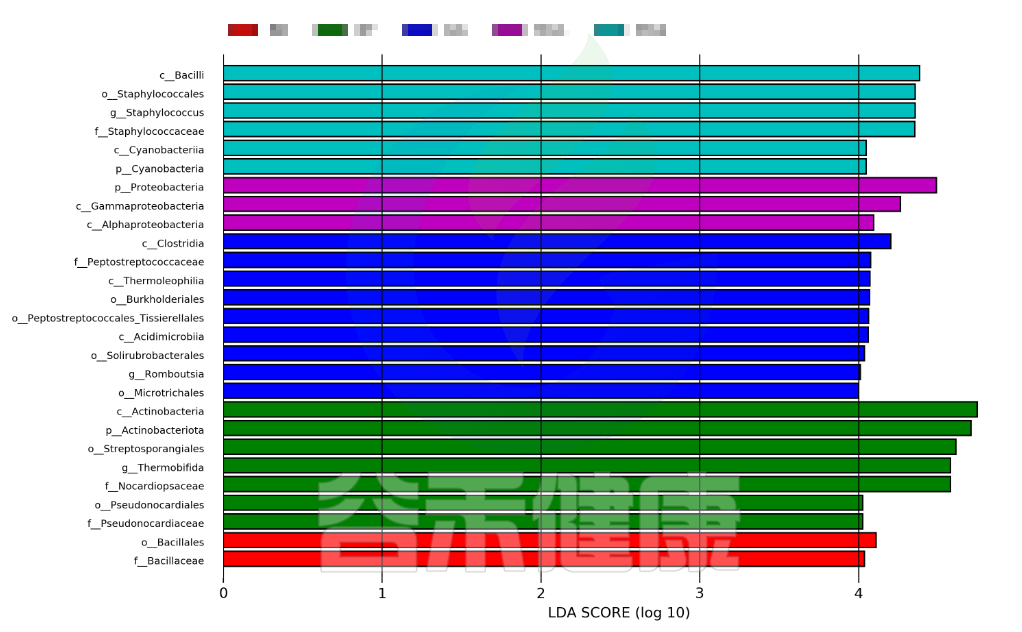
图中展示了不同分组特有的Lefse组间差异标记物,例如BB组的标记物是目水平的Bacillales和科水平的Bacillaceae,不同的分组标记物也不同,图中如果只展示了部分分组,则代表只有部分分组通过Lefse分析筛选出组间差异标记物。
进化分支图
小圆圈: 图中由内至外辐射的圆圈代表了由门至属的分类级别(最里面的那个黄圈圈是界)。不同分类级别上的每一个小圆圈代表该水平下的一个分类,小圆圈的直径大小代表了相对丰度的大小。
颜色: 无显著差异的物种统一着色为黄色,差异显著的物种Biomarker跟随组别进行着色,红色节点表示在红色组别中起到重要作用的微生物类群,蓝色节点表示在蓝色组别中起到重要作用的微生物类群。
未能在图中显示的Biomarker对应的物种名会展示在右侧,字母编号与图中对应(为了美观,右侧默认只显示门到科的差异物种)。
路径:Group/Lefse_Analysis/out_formant.png
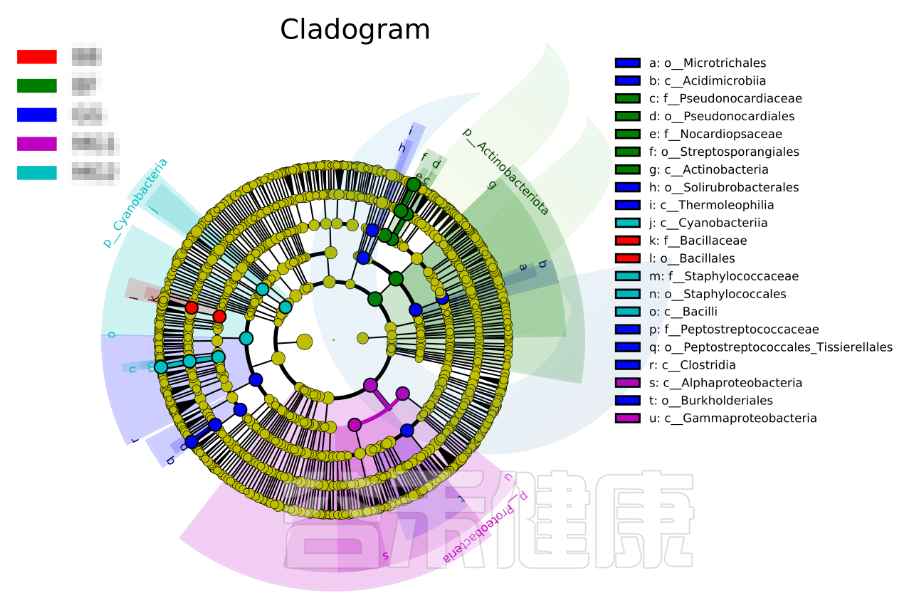
图中右侧展示了分支图中的字母对应的物种信息,例如a 代表GG组的标记物目水平的Microtrichales ,b代表GG组的标记物刚水平的Acidimicrobiia。在分支图的最外层显示的是各分组门水平物种的标记物,例如BF组的是Actinobacteriota、MG1组的是Proteobacteria、
MG2组的是Cyanobacteria
特征表
路径:Group/Lefse_Analysis/out_formant.res.csv
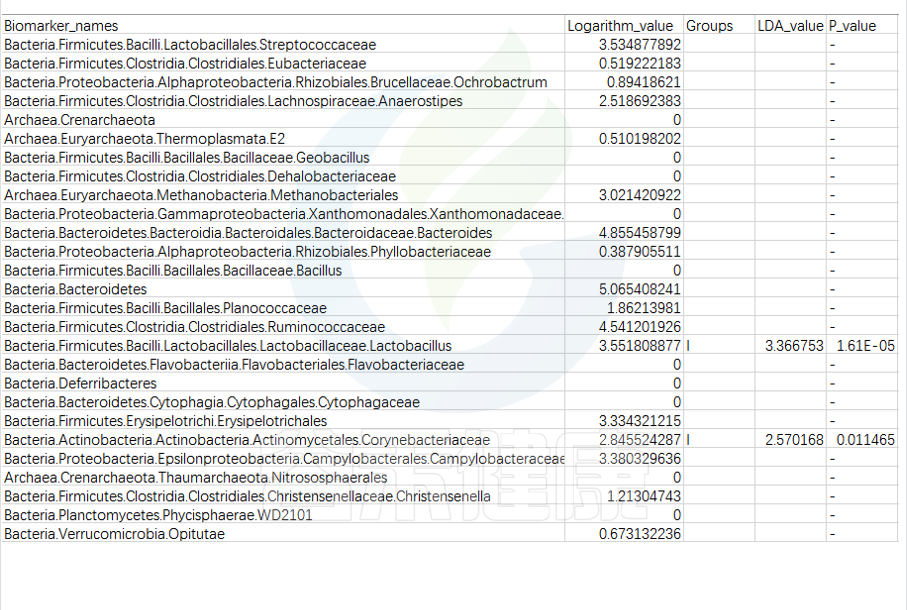
第一列是样本中从门到属水平所有分类单位的列表
Lefse会逐一判断这些分类单位的在分组之间是否具有统计学显著性差异。
第二列:各组分丰度平均值中最大值的log10,如果平均丰度小于10的按照10来计算;如果该分类单位未体现出显著组间差异,则后三列为空。
对于具有统计学差异的分类单位:
第三列:差异基因或物种富集平均丰度最高的分组组名;
第四列:LDA差异分析的对数得分值;
第五列:Kruskal-Wallis秩和检验的p值,若不是Biomarker用“-”表示。
默认LDA>2,P<0.05
通常根据第4列的LDA差异分析对数得分值和第五列的P值,可以描述组间具有显著差异的分类单位统计学效力强弱。
metagenomeSeq
metagenomeSeq是用R开发的一个包,metagenomeSeq的基本思想,用normalization实现分类注释时的biases处理,同时用零膨胀高斯分布(zero-flated Gaussian distribution)处理了测序深度所带来的影响,在此基础上,利用线性模型找到存在的差异所在。
路径:Groups/diff_analysis/ metagenomeRXXX
metagenomeSeq 差异显著物种/功能 热图
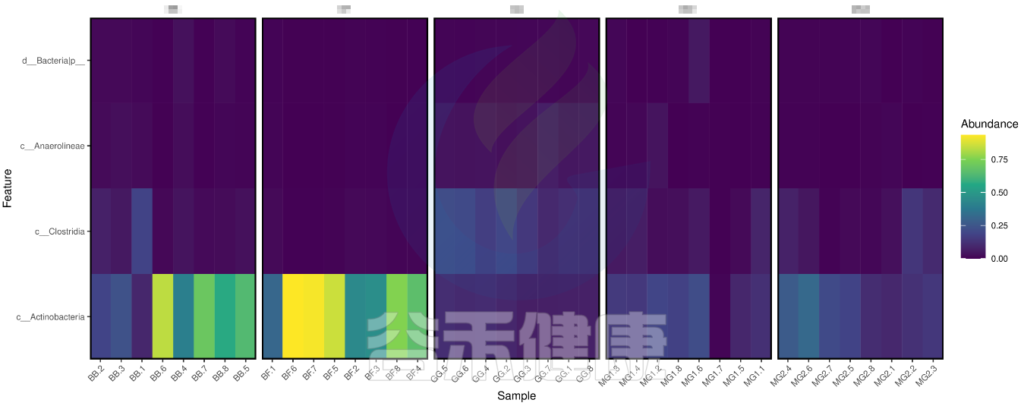
图中颜色越深相关性越小,颜色越接近黄色相关性越大,从图中能看出Actinobacteria物种与BB组和BF组相关性较大。
metagenomeSeq差异菌属于功能代谢关联分析
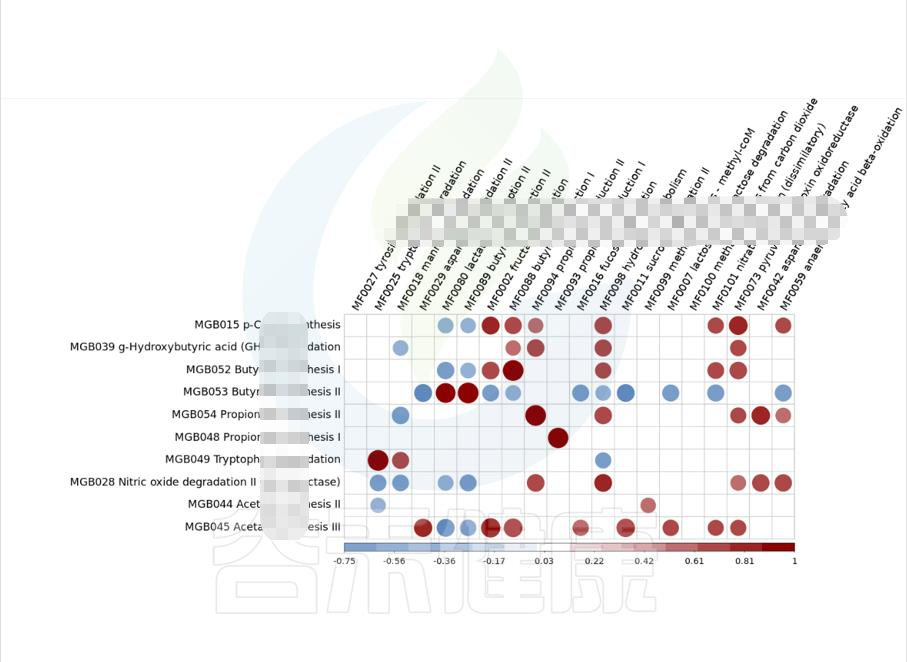
图中红色代表正相关,蓝色代表负相关,颜色越深,圆圈越大,相关性也越大,例如图中能看出MGB049余MF0025 之间成正相关,且相关性较大。
随机森林模型
一种非线性分类器,随机森林属于集成类型的机器学习算法,挖掘变量之间复杂的非线性的相互依赖关系。通过随机森林重要性点图,可以找出分组间差异的关键物种/功能。
反映了分类器中对分类效果起主要作用的特征,按重要性从大到小排列。
Error rate:表示使用下方的特征进行随机森林方法预测分类的错误率,数值越高表示基于特征分类准确度不高,可能分组之间特征不明显。分值越低证明分组效果比较好。
•举个例子
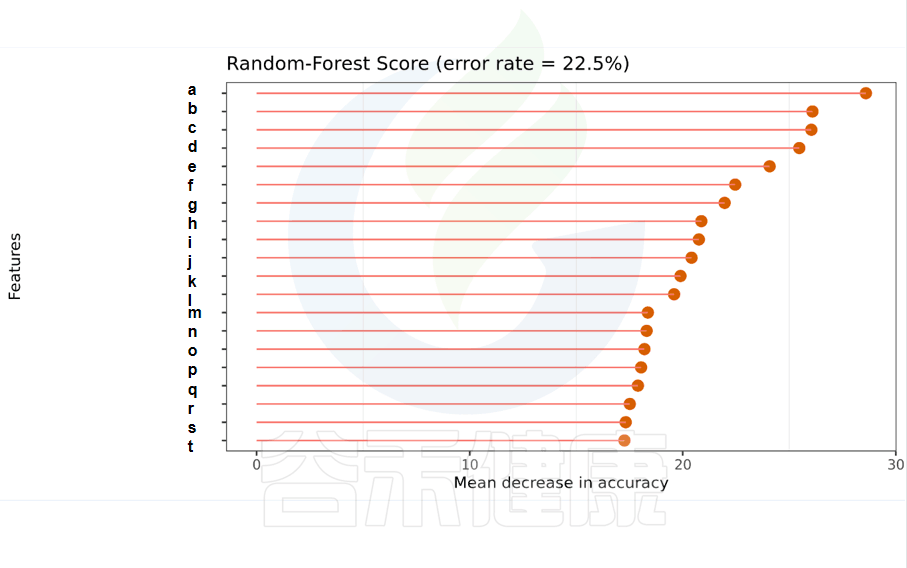
图中按照随机森林模型效果筛选出的对分组效果有重要性作用的物种,按照重要性从高到低进行排列,例如图中最终要的是a,依次往下是b、c等。错误率较小,表明该分组效果较好。
ROC曲线
ROC曲线分析是一种常用的统计学分析方法,在医学研究中主要用于评价诊断试验的效能。在16S测序报告中,我们通过绘制ROC曲线,并计算ROC曲线下面积(AUC),来确定分组对于菌群是否有诊断价值。
ROC曲线图是反映敏感性与特异性之间关系的曲线。ROC曲线下的面积值在1.0和0.5之间。在 AUC>0.5的情况下,AUC越接近于1,说明诊断效果越好。
AUC在0.5~0.7时有较低准确性,AUC在0.7~0.9时有一定准确性,AUC在0.9以上时有较高准确性。AUC=0.5时,说明诊断方法完全不起作用,无诊断价值。AUC<0.5不符合真实情况,在实际中极少出现。
•举个例子
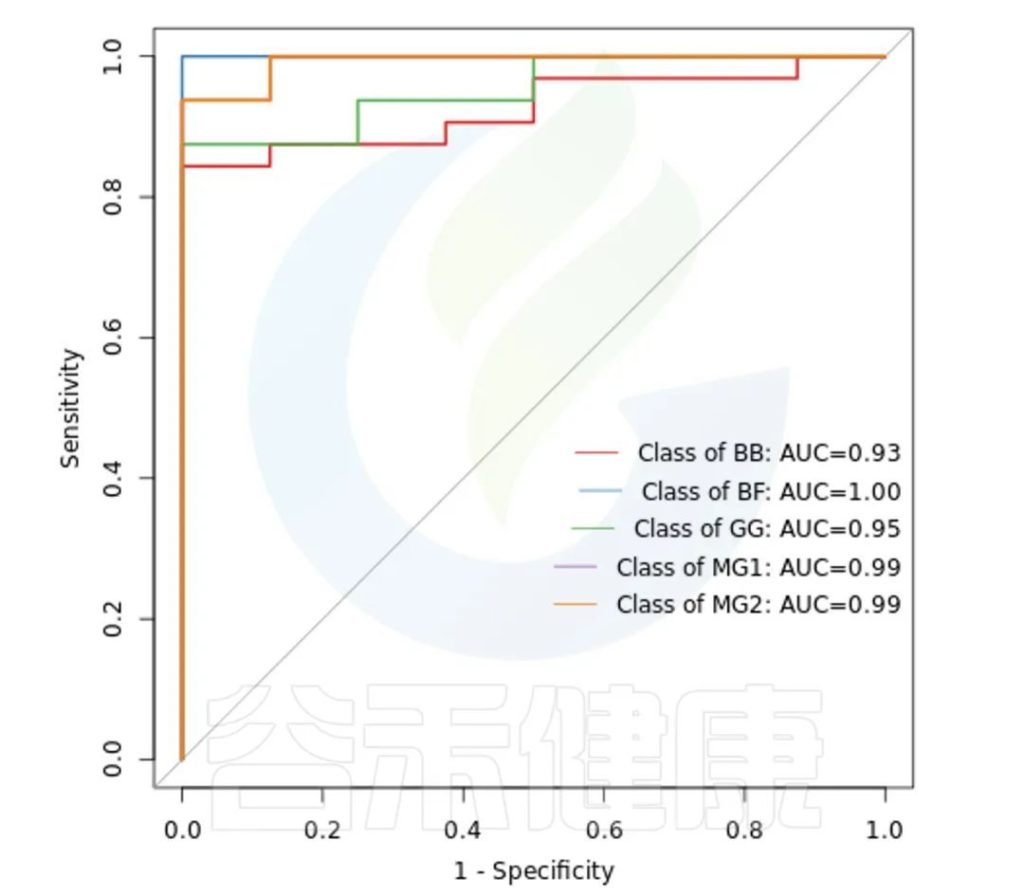
从图中能看出各分组的AUC都大于大于0.9,各分组的分组效果较好,BF组AUC等于1,该分组效果最好,可能样本之间较为相近,并且跟其他分组组间差异也比较大。
以上是组间统计差异的方法介绍,其他的还包括关联分析。
例如客户提供了每个样的相关理化指标数据,想计算这些指标与均属之间有什么相关性,就可以做一下分析。
关联性分析
✦相关性热图
图中X轴代表属水平物种,Y轴代表代谢指标,红色代表正相关,蓝色代表负相关,**代表相关极显著P<0.01,* 代表相关性显著P<0.05相关性具有统计学意义。
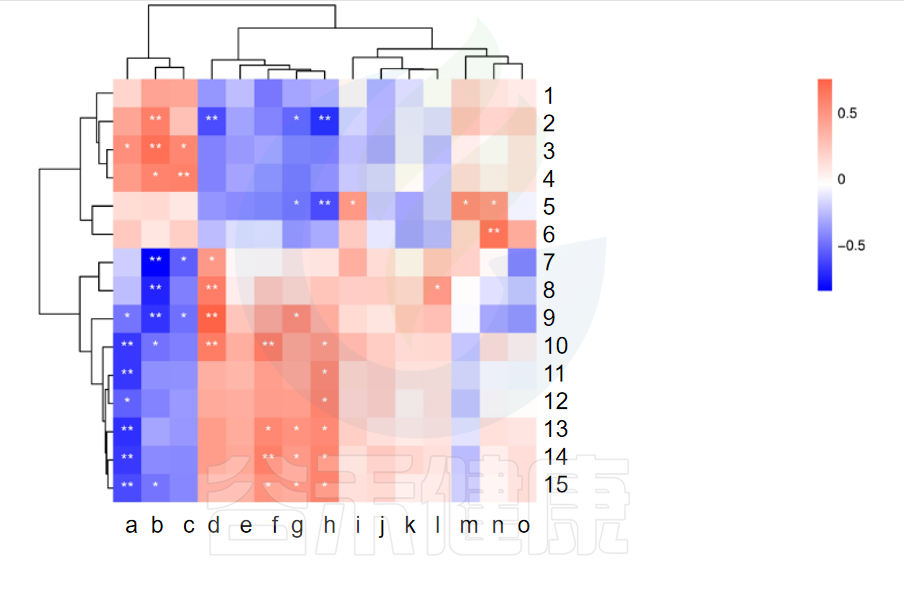
例如从该图中能看出6与n物种成正相关,并且相关性极显著**,7与b物种成负相关,并且相关性极显著**。
可以得到表格:任意菌属和代谢的相关性的值和P值
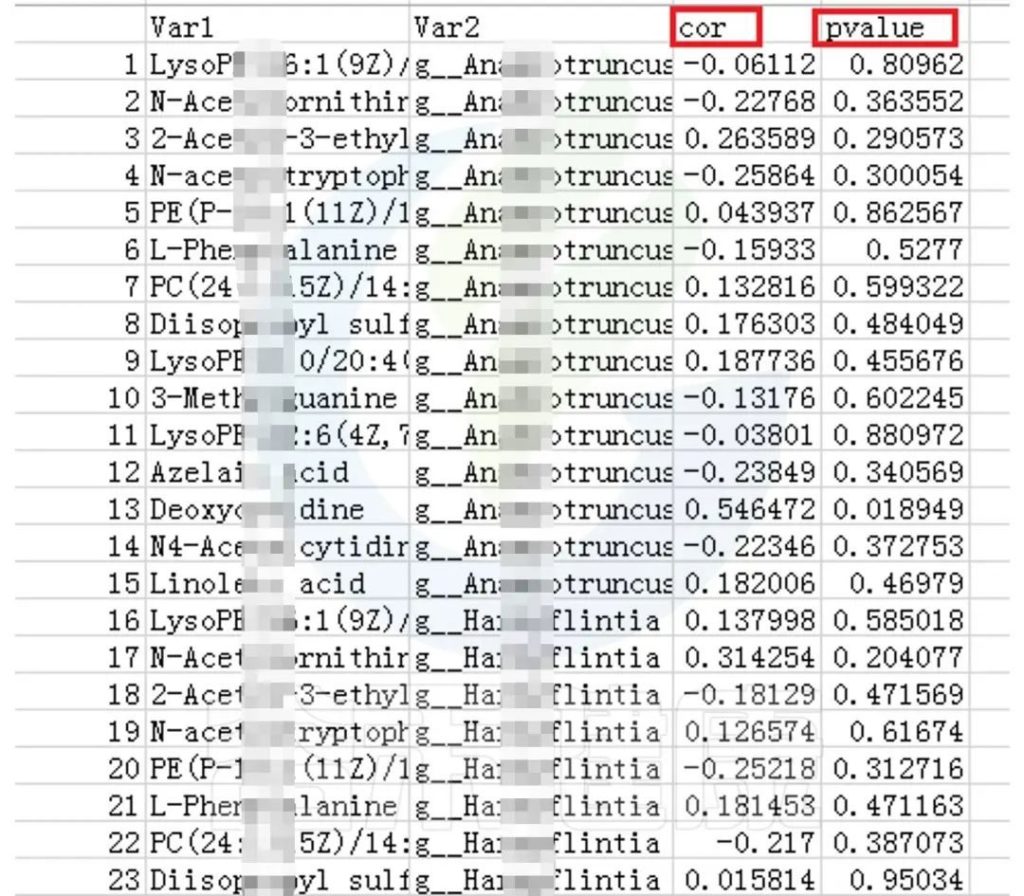
✦CCA图
可以分析样本、菌群、理化指标之间的关联关系。图中使用点代表不同的样本,从原点发出的箭头代表不同的环境因子。
箭头的长度越长,表示环境因子的影响越大;夹角越小,代表相关性越高。样本点与箭头距离越近,该环境因子对样本的作用越强。
图像中坐标轴标签中的数值,代表了坐标轴所代表的环境因子组合对物种群落变化的解释比例。
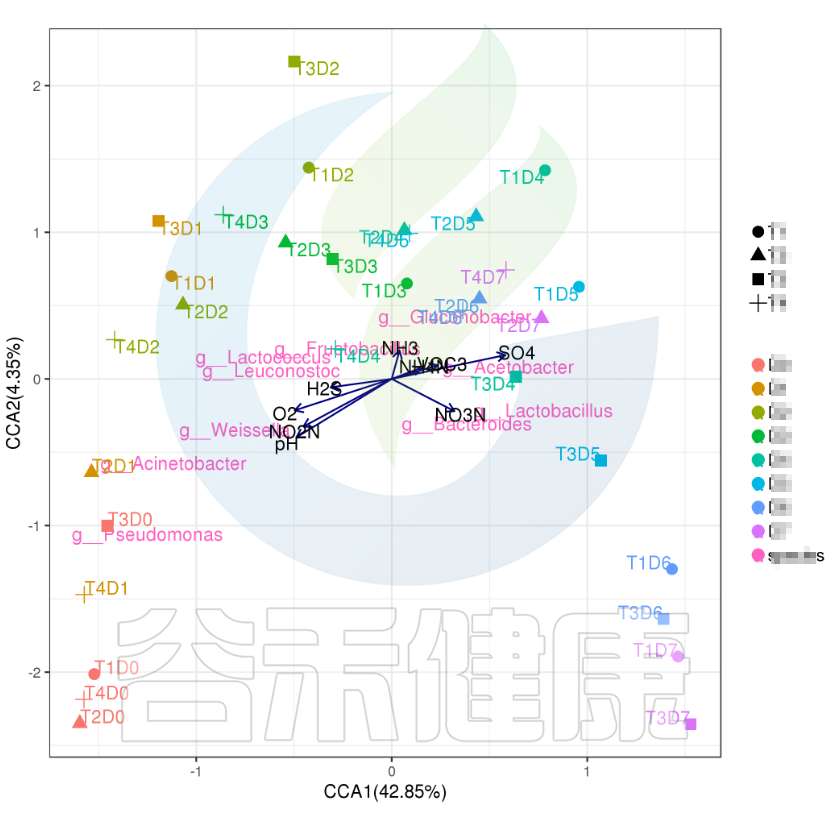
例如从图中能看出pH 、NO2N、02与 Acinetobacter、Weissella等物种成正相关,与T3D0、T1D0、T4D0等D0组的样本成正相关。
✦RDA 冗余分析

例如从图中能看出pH与Helicobacer物种成正相关,相关性较大,pH与NC组有一定的相关性。
✦Envfit分析
回归拟合分析结果:
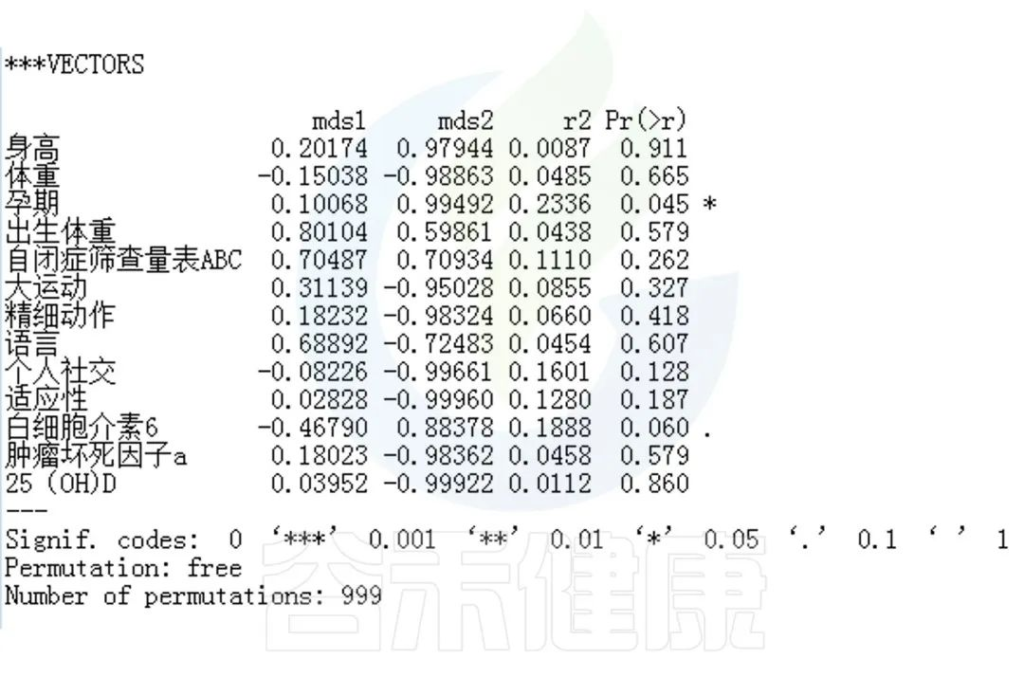
图中能看出ASD与正常儿童之间的分组与菌群之间相关性极显著**,其次是否有先兆流产的分组与菌群之间有显著相关性*,其他的包括是否喝牛奶、孕期是否感染、妊娠高血压都与菌群有相关性。
环境因子与功能/物种的相关性线形图P<0.05显著,图中红色点代表正相关,绿色点代表负相关,灰色相关性不显著。
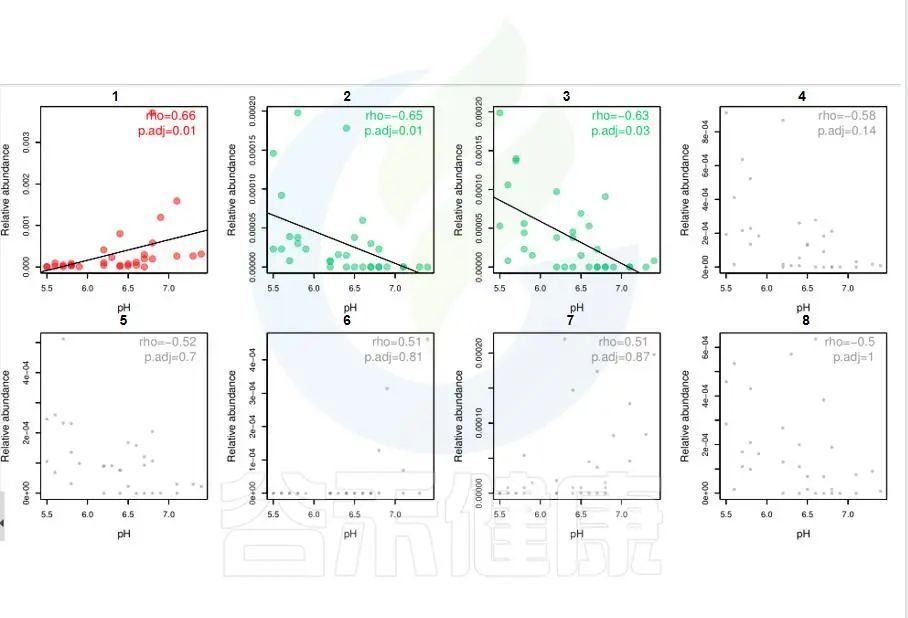
图中能看出pH 与Candidatus Rhabdochlamydia 之间成正相关,且相关性显著,pH 与Sinorhizobium、Euzebya 之间成负相关,切相关性显著。
✦Network网络分析
还可以做菌属之间的网络分析关联图,共发生网络图为研究复杂微生物环境的群落结构和功能提供了新的视角。
由于不同环境下微生物的共发生关系截然不同,通过物种共发生网络图,可以直观看出不同环境因素对微生物适应性的影响,以及某个环境下占互作主导地位的优势物种、互作紧密的物种群,这些优势物种以及物种群往往对维持该环境的微生物群落结构和功能稳定发挥着独特以及重要的作用。
•举个例子
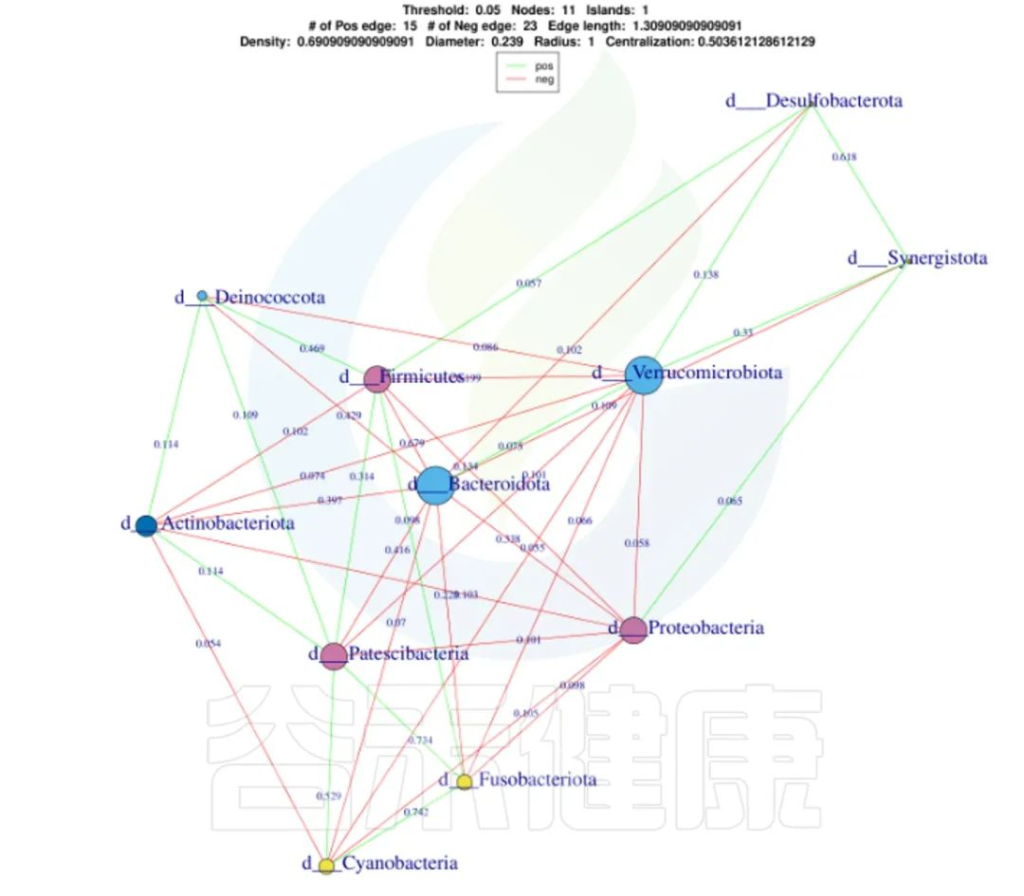
图中展示了相关性的物种,例如Bacteroidota、Actinobacteriota、Proteobacteria 这些物种与其他物种相关较大,图中这些物种与其他物种连线较多,字体比较大也代表相关性较强,例如Actinobacteriota与Deinococcota连线是绿色的代表这两个物种是负相关。
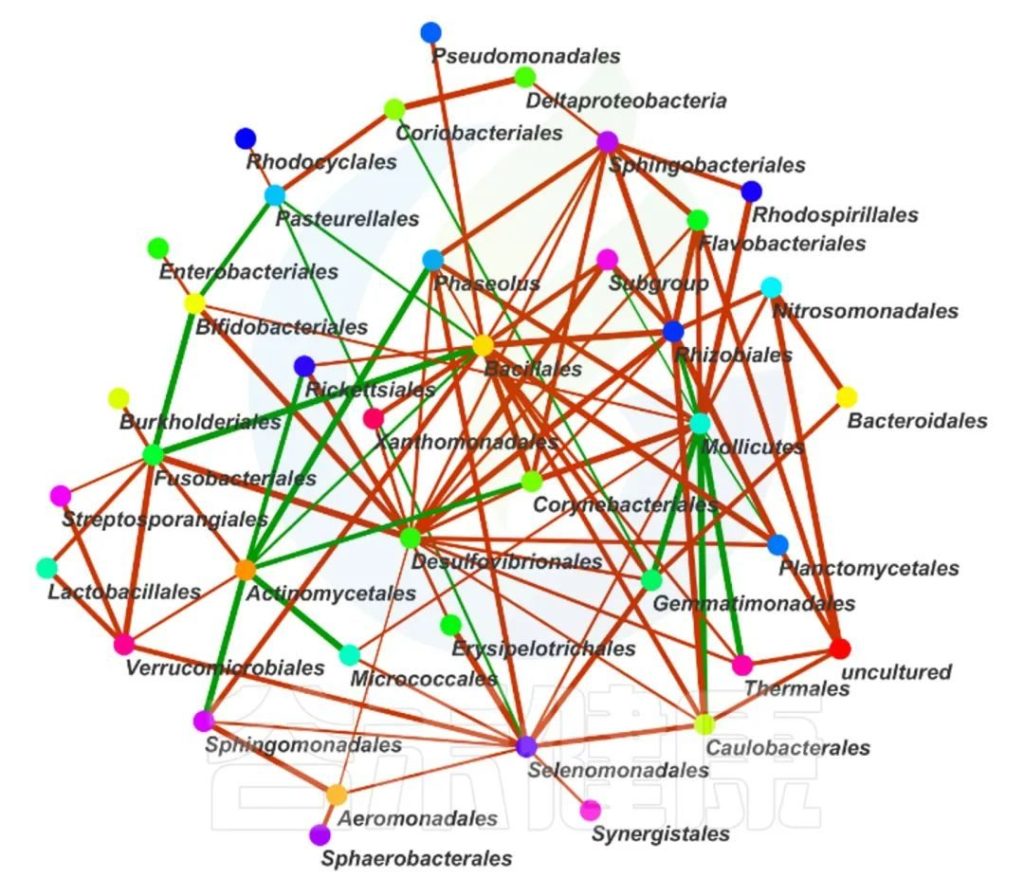
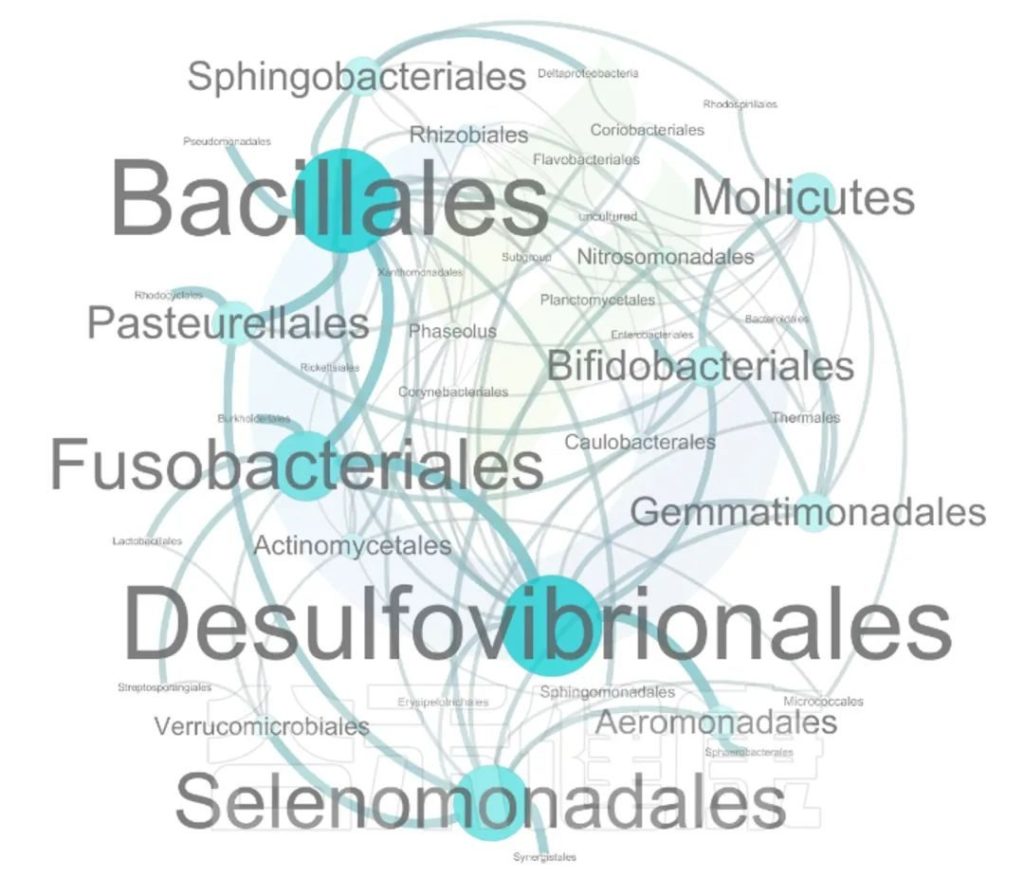
这两个图类似的物种相关性的图,用同一个数据做出来的,图中能看出Bacillales、Desulfovibrionales、Selenomonadales与其他物种相关性较强。
报告中已经基本都涵盖了16S科研数据分析所需要的图表、差异统计,以及相关性分析结果。如果在几种不同类型的统计方法对比之下有略微的差异结果,选取其中一组差异结果即可。
报告里涵盖了大部分16S所需要的图片,不过也有个别个性化的图需要单独用到软件去做,可以单独完成个性化图表生成。
随着16s分析报告的不断升级,报告中的图表以及相应的解读也会越来越精细完善,谷禾也将尽可能为大家的科研之路带来更多便利。


谷禾健康
迄今为止,已经有了许多对呼吸道微生物组通过16S rRNA高通量测序的研究。这其中所有基于扩增子的研究的共同之处就是PCR的应用:
一是扩增待测序的目标标记基因,
二是为多样本的混合测序添加必要的索引序列。
这些步骤可以通过一步PCR或两步PCR完成,但没有研究说明两步PCR方案相关的实验室处理步骤是否会使样品比一步PCR方案更容易受到来自实验室的细菌DNA污染的影响。
本文
试图确定对16S rRNA V3V4与V4基因区域的一步或两步PCR的建库方案对上呼吸道和下呼吸道微生物组的影响
对收集的样本进行了三个设置下的lllumina MiSeq测序
设置1(两步PCR,V3V4区域)
设置2(两步PCR,V4区域)
设置3(一步PCR,V4区域)
分别对这三个设置产生的测序数据进行分析
结论
PCR步骤数量的差异会影响对呼吸道微生物群落的物种组成分析,且对上呼吸道(高细菌载量)的影响小于下呼吸道(低细菌载量),这表明PCR设置的偏差与样本生物量有关。
通过三个实验,即对模拟群落样品HM-783D、NCS样品、呼吸道样品采用三种PCR方案进行建库后的测序结果分析,研究这三种建库方案对其菌群描述的影响。
模拟群落样品HM-783D,来自20种不同细菌物种(17个属)的基因组DNA。
阴性对照样本NCS
呼吸道样品,从Bergen COPD微生物组研究中选择了23名研究对象,其中9名健康,4名患哮喘,10名患COPD(慢阻肺)。上呼吸道样本以漱口水(OW)为代表,下呼吸道样本以标本刷(PSB)和支气管肺泡灌洗液(PBAL)为代表。
三种PCR方案:
细菌DNA提取后通过三种不同的建库设置进行MiSeq测序,分别为
Setup1(两步PCR,V3V4区域);
Setup2(两步PCR,V4区域);
Setup3(一步PCR,V4区域)
下图完整的展示了三个PCR设置下的使用呼吸道样本的生物信息学过滤步骤:
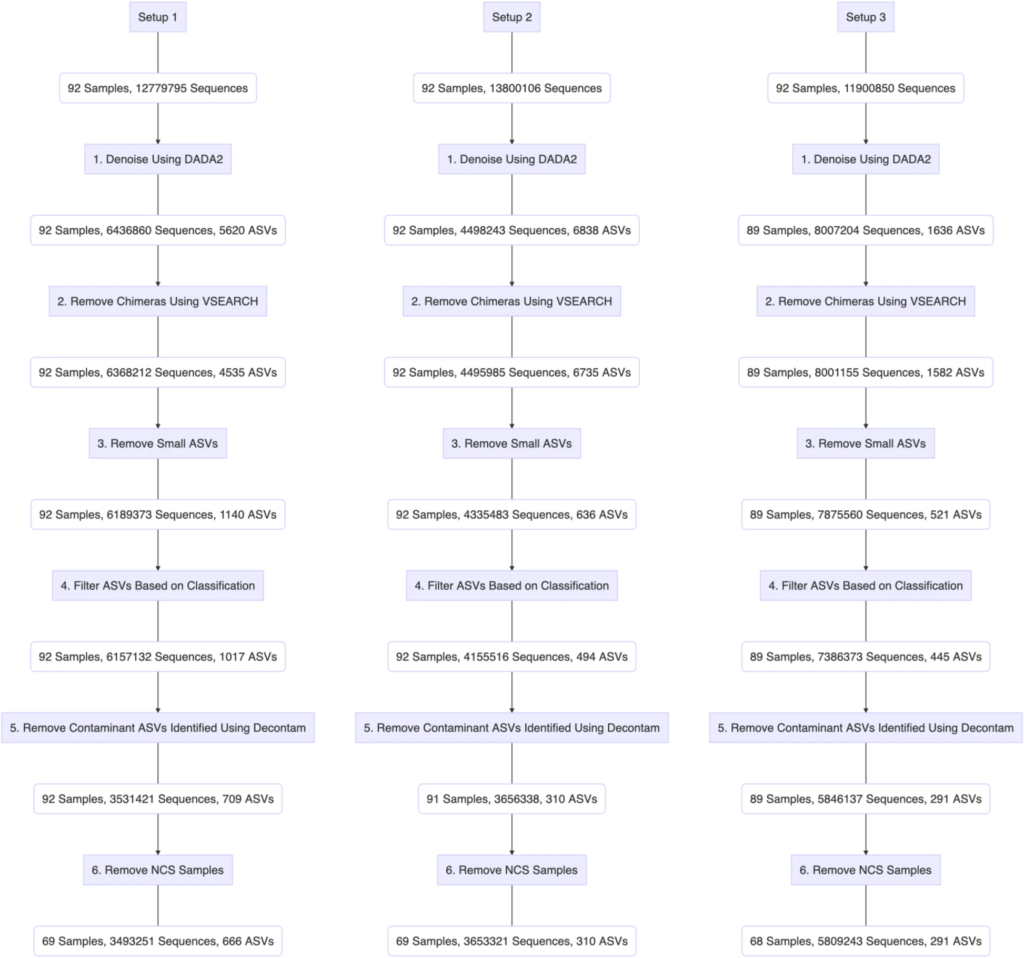
最终:
设置1:得到了666个ASVs
设置2:得到了310个ASVs
设置3:得到了291个ASVs
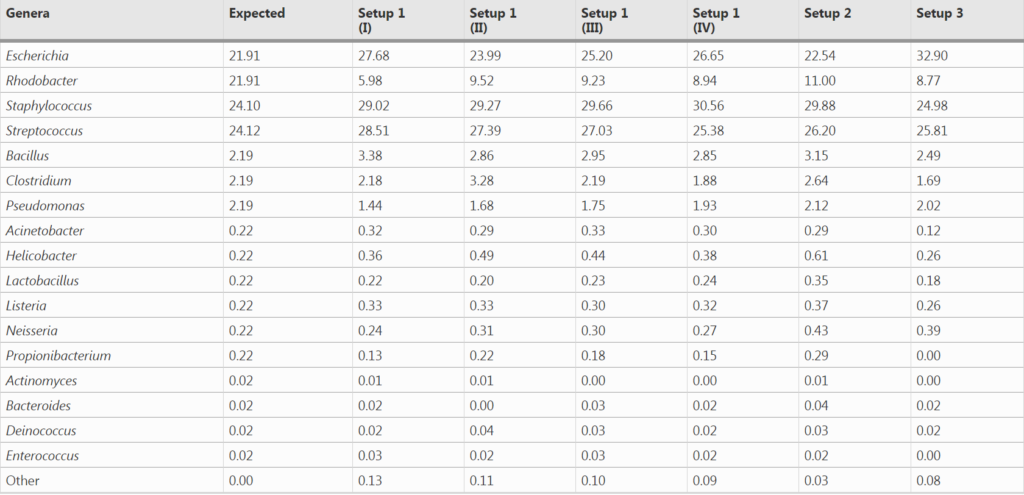
1. 对模拟群落样品HM-783D的分析
在设置1中进行了四次测序,设置2和设置3分别进行了一次。
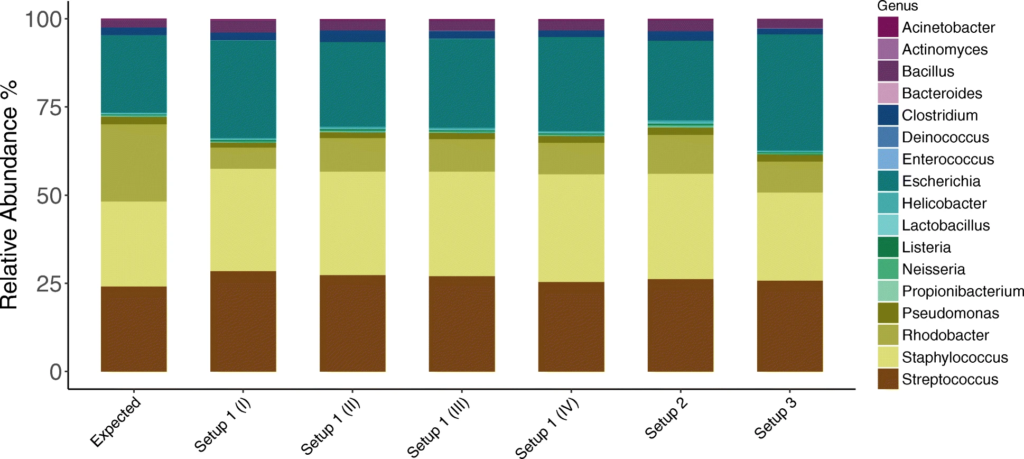
与预期丰度(Expected)相比,柱状图中观察到三种PCR设置下的各菌属的相对丰度与预期丰度相差不大,表中数据显示,三种PCR设置都在恢复高丰度物种方面具有最高的效率,但设置3在回收低丰度物种时的效率最低。
2. 对阴性对照样品的分析
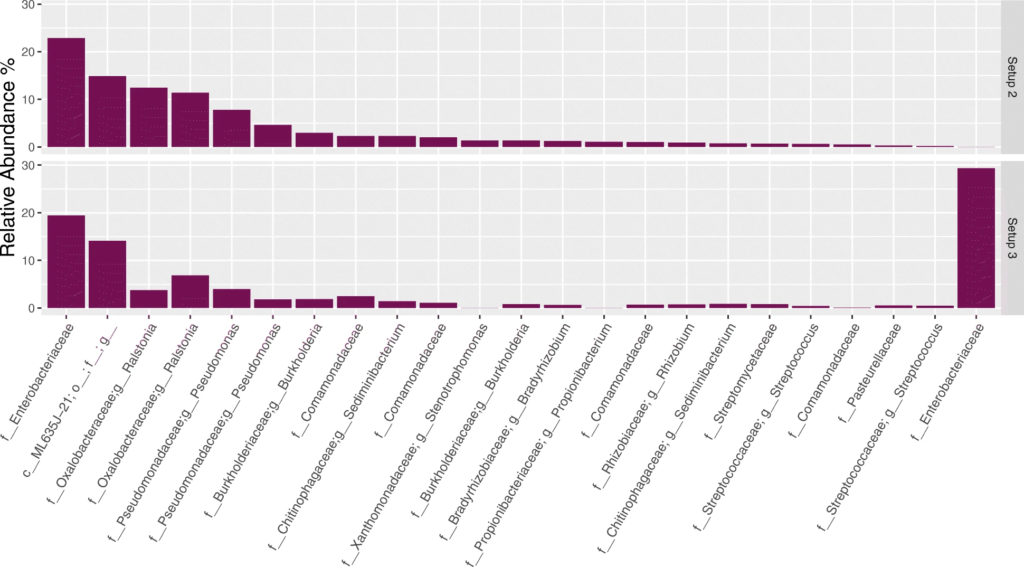
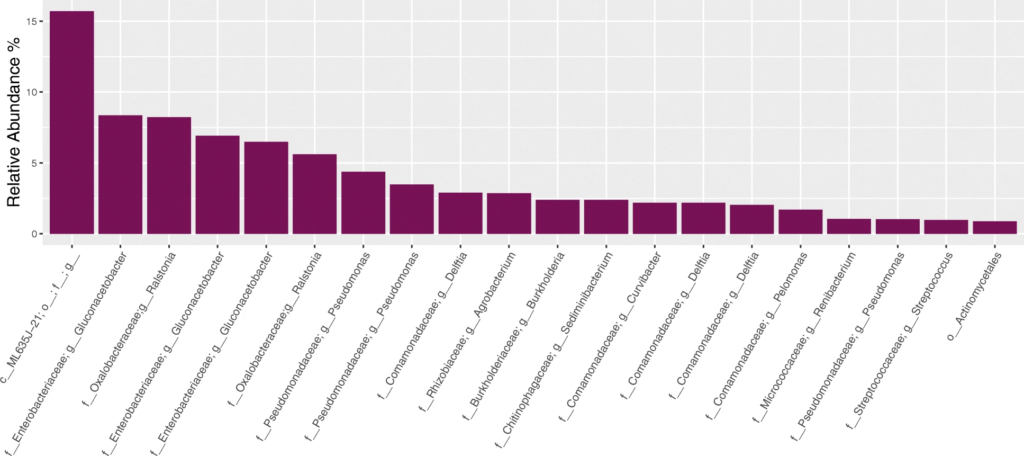
从上至下分别为设置123测序后,在NCS样品中观察到的20种最丰富的ASV。通过R包Decontam去除污染物,在设置23之间差异最大的是属于肠杆菌科的ASV,与后续的对水样品进行设置23下的测序分析结果相比较,发现大肠杆菌ASV就是在建库步骤中使用设置3的试剂时引入的污染物。
3. 对采集的呼吸道样品的分析
在去除污染物前后,代表为呼吸道菌群的链球菌,普雷伏氏菌,Veillonella和Rothia属的相对丰度变化不大,而去除污染物后,预测作为污染物代表的数量较少的物种被滤出。基于主坐标分析,发现高细菌载量的OW样品聚集在一起,低细菌载量PBAL,PSB一句设置23分离开。
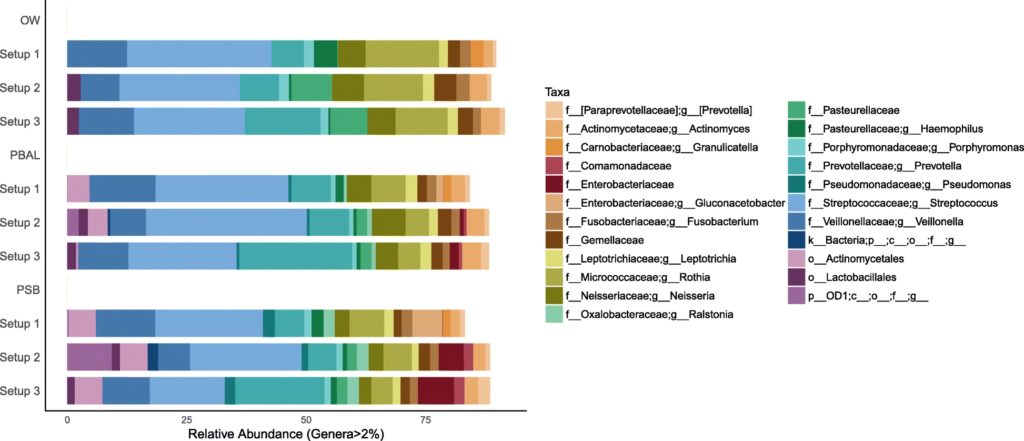
去除污染物之前的三种类型样品的三种PCR设置下的物种分类
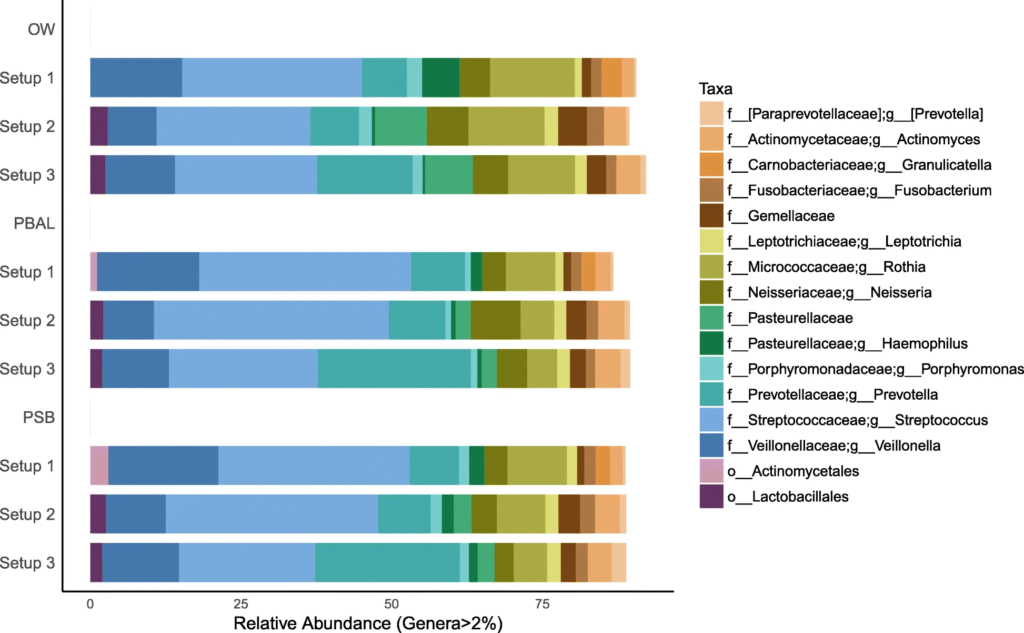
去除污染物后的
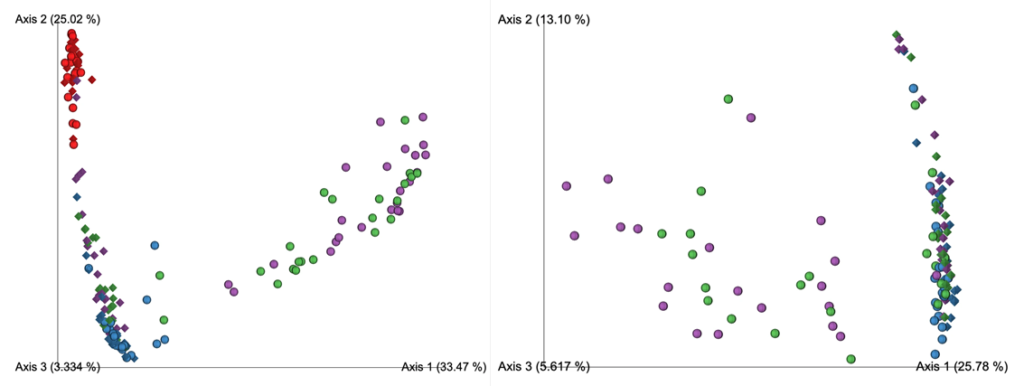
从左至右分别为去除污染物前后的未加权UniFrac距离的主坐标分析
OW:蓝色; PBAL:绿色;PSB:紫色;NCS:红色。
设置2(球形),3(菱形)
文章作者给出的结论是文库制备和测序方法的选择会对呼吸道微生物组的分析产生影响,且对上呼吸道的影响小于下呼吸道。靶向扩增子区域的差异(16S rRNA基因V3 V4与V4)并未表现出对细菌群落描述的重大影响。对于整篇研究存在的主要的局限性在于仅研究了DNA提取后的PCR步骤,污染或影响也可能来自于更前期的处理。
编者按
在使用测序技术进行的微生物研究中,测序偏差和污染物是一直存在的问题,也因此诞生了许多工具和计算方法用于尽可能的消除或降低这方面的影响。这篇研究也提醒了我们,在呼吸道微生物组的研究中,要注意上呼吸道与下呼吸道的菌群差异或相似可能不仅仅来源于样本自身,还可能掺杂着PCR方法选择上的影响。
参考文献:
Drengenes C, Eagan TML, Haaland I, Wiker HG, Nielsen R. Exploring protocol bias in airway microbiome studies: one versus two PCR steps and 16S rRNA gene region V3 V4 versus V4. BMC Genomics. 2021 Jan 4;22(1):3.
相关阅读:

谷禾健康


在现代测序技术的帮助下,微生物组研究的范围被扩大,通过16S rRNA测序或鸟枪法宏基因组测序可以生成大量的微生物组数据。而微生物群落研究中的一个重要问题是对这些微生物的归类,模拟和分析人类微生物群。
通常使用16S rRNA技术量化微生物群落的组成,但量化后的数据是偏斜的,带有过多的0。目前还缺乏对复杂的微生物群落测序数据的标准化的聚类分析方法。
近日,加拿大多伦多大学研究人员在《Microorganisms》上发表的一篇研究,针对上述问题构建了一个参数化的混合模型用于计算聚类分析的距离度量,模型根据观察到的OTU计数和估计的混合权重产生sample-specific的分布。这个方法可以准确的估计真实的0比例,从而构建一个精确的beta多样性度量。
大量的模拟研究表明,与一些被广泛使用的距离度量方法相比,当存在较大比例的0时,该方法取得了较好的聚类效果。
该研究人员提出了一种具有特定beta多样性度量的聚类算法,该算法可以解决稀疏计数数据遇到的有无偏差问题且能有效的度量样本距离,达到分层的目的。
微生物群落研究中的一个重要问题是对这些微生物的归类,它们是否能被划分为亚群。如果有,有多少组亚群,如何解释这个亚群。例如,这种分类是否区分了治疗方法、疾病或遗传类型。
为了回答这些问题,需要测量两个微生物群落之间的相似性。beta多样性是为了适应不同的目的而提出的,在评估群落之间的差异时提供不同的结果。对于微生物组成,beta多样性根据测量丰度来衡量群落之间的距离,丰度可以是观察到的计数,也可以是相对丰度,这些丰度是根据不同或距离度量计算出来的,以量化样本之间的相似性。
现如今,已经有许多非参数统计方法来量化距离度量。例如Euclidean和Manhattan距离是最常用的。其它beta多样性指标,例如Bray-Curtis距离、Jensen-Shannon距离、Jaccard指数、UniFrac距离(未加权的、加权的和广义的)也经常用于微生物组研究。
除了距离度量之外,还引入了用于生态关联推理的稀疏逆协方差估计(SPICE-EASI)的图形网络模型。然而这些方法都会有一定的局限性,例如SPIEC-EASI方法依赖于单一的方差-协方差矩阵,由于微生物群落结构复杂,可能无法完全恢复底层OTU网络。
于是,研究人员开发了一种创新的聚类方法,以混合模型而不是beta多样性度量作为距离度量,并将聚类算法应用于微生物群落数据来表征亚群。该算法还包括根据选择的内部指标选择最优聚类数,并将结果在几种距离度量和不同评估方法之间进行比较。通过全面的模拟研究和一个真实的帕金森病肠道微生物群数据集对该算法的性能进行了评估。
1. 构建混合模型
混合模型是一种概率模型,用于表示在无监督学习中经常使用的总体内的子群体。该模型关注单个OTU在种群中的分布,可以解决样本间的稀疏性问题。它参数化地模拟了计数的潜在分布,包括低计数OTU和极高计数。对于个体样本之间的成对距离,在L2范数距离中使用公式化的混合概率。
2. 距离度量
在确定混合模型分布后,使用概率分布通过样本之间的两两距离计算距离度量。为了进行比较,考虑了基于L2范数的三种距离度量(L2-PDF、L2CDF、L2-DCDF、L2-CCDF)。
除此之外还选择了一些其他的距离度量进行比较,即Manhattan距离和Euclidean距离,以及微生物组分析中特有的三个距离度量:Bray-Curtis距离、加权UniFrac距离和广义UniFrac距离。本研究不考虑未加权的UniFrac距离,因为它不包含类群丰度信息。
3. 聚类分析验证指数
这些指数用于衡量集群在集群内部和集群之间的可分离性表现很好。验证指标可以分为内部指标和外部评估,许多内部验证指标被用来选择最优聚类数。外部评估分数是在假设标签在建模阶段没有使用时,通过直接将划分结果与之前的标签进行比较来计算的。
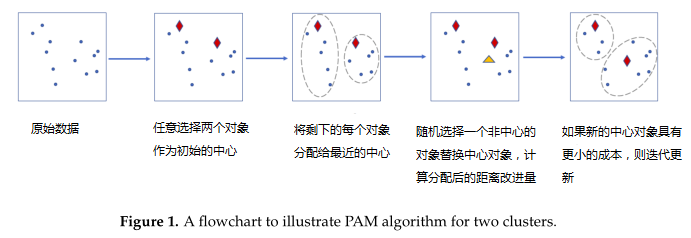
4. 用于聚类的分区算法(PAM)

使用混合分布的聚类过程的详细步骤:
为了测试该方法在聚类中的表现如何,研究人员推导了其准确性和Jaccard指数。
准确性是指聚类结果与真实的聚类指数的接近程度。它被定义为正确聚集的受试者所占的比例。
Jaccard指数衡量聚类结果与原始聚类标签之间的相似性,原始聚类标签定义为正确分类的主题数量(预测集与真实集的交集 )与两组总样本量(两集的并集)之比。
研究人员用类标签模拟数据来模拟OTU计数及其复杂的结构。研究人员考虑两个有两个子类和三个子类的场景,每个子类包含200个样本,总样本量分别为400和600。所有的结果被重复了100次。
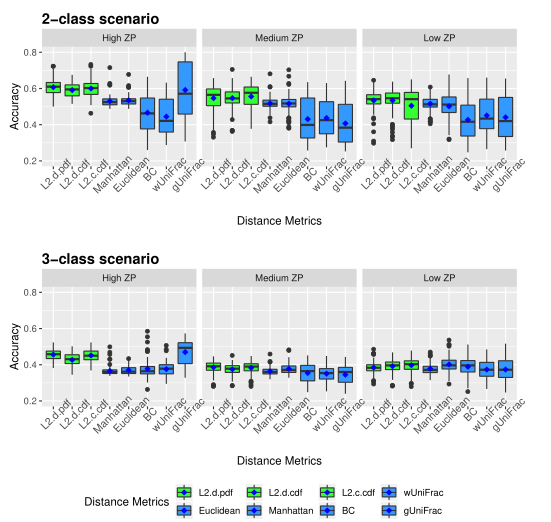
下图展示了模拟数据的准确性。评估了三种不同的0的比例(ZP)情况,左中右分别为高ZP、中等ZP、低ZP。
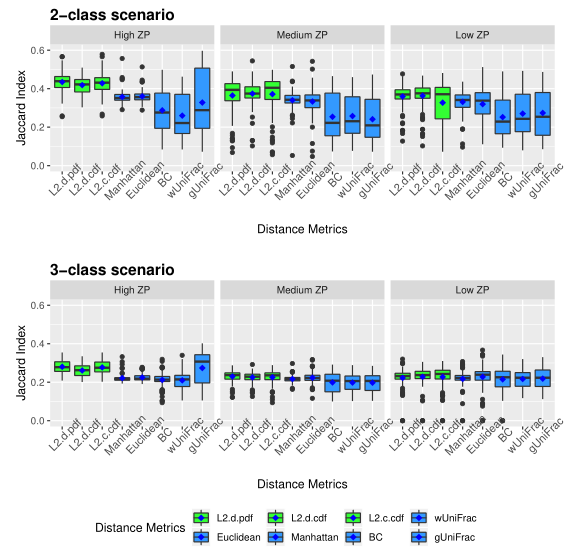
下图展示了模拟数据的Jaccard指数。同上图一样评估了三种不同的0的比例。
以上两图显示了具有不同ZP和子类数量的不同场景下模拟数据集的聚类结果。通过准确率和Jaccard指数对基于距离的算法性能进行了评估。填充颜色为绿色的箱形图为研究人员建议使用的距离度量。所有的距离都是根据相对丰度计算的。
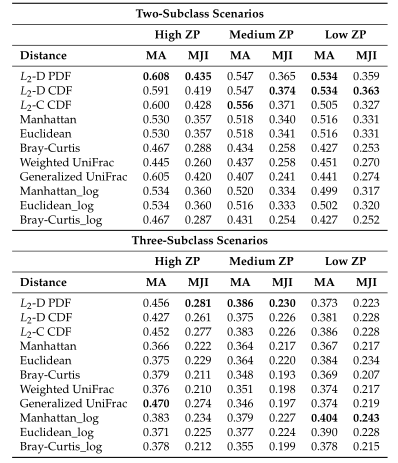
Table1平均准确率(MA)和平均Jaccard指数(MJI)估计。粗体表示每个方案下的最佳情况。Log表示对输入的模拟数据进行了对数变换。
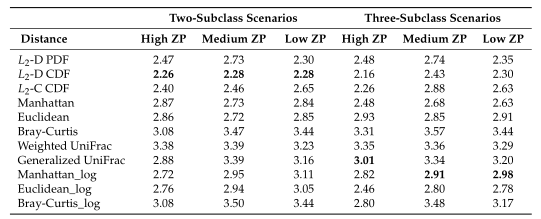
Table2所有模拟场景的平均集群数。根据Dunn内部指数计算出每次重复的最优聚类数。
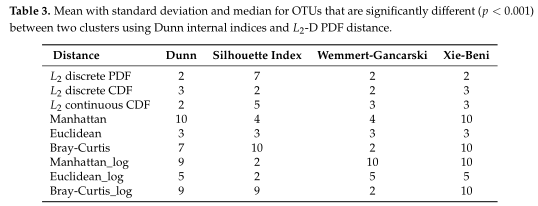
Table1 的结果是通过对每个场景中的100个重复结果求平均值计算得出的。观察得到在聚类算法中实现的距离度量(即绿色标识的箱形图)的准确率和Jaccard指数都优于其他距离度量,特别是在数据集中包含大量0时(高ZP)。在MA和MJI方面,L2范数也显示了其优势,在基于100次重复计算的L2范数在两个子类场景下的;平均准确率约为0.6秒,在三个子类场景下的平均准确率为0.45。而广义Unifrac距离(gUniFrac)在准确性估计中有很大的波动变化。
数据集为197名PD患者和130名对照的粪便样本的16S rRNA测序数据。首先过滤掉在80%的OTU中相对丰度都为0的OTU,因此,此次分析中共使用280个OTUs。将基于相对丰度计算的L2范数与其他三个距离度量进行了比较,包括对数变换和不变换的比较。
如Table3所示,距离度量采用各种内部验证指标(列名)进行灵敏度分析。对于Dunn和Xie-Beni指数,l2范数倾向于将数据聚类为两到三个亚群,而在有和没有对数变换的情况下,除了未变换的欧氏距离外,Manhattan、Euclidean和Bray-Curtis更倾向于聚类更多的亚群。(设置了最多聚类数目为10)
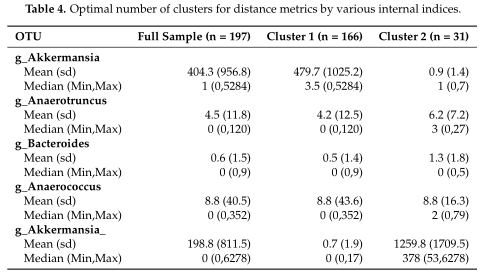
接着选择L2-D PDF范数作为进一步分析的例子。
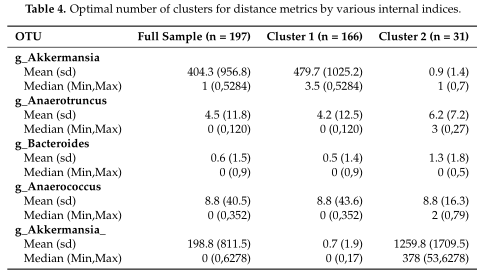
结果在Table4中展示,对数据集中的两个集群之间的OTUs进行了探索,得到了聚类之间差异最大的前5个OTU。
研究认为该聚类算法在高ZP和中等ZP的情况下表现最好,因此,当数据中出现大量的0时,建议使用。并且,在PAM框架下,文章中列出的那些距离度量都可以用作聚类的输入。
如模拟研究中显示的那样,在各种场景下,由混合模型计算的成对距离比其他距离度量表现的更好。但是与所有聚类方法一样,都有一个局限性,就是很难为每个新数据选择合适的内部指标,因此很难获得最优和最稳健的集群数。
此外,对于L2范数距离,在聚类中无法进行变量选择。但不可否认,该聚类算法结合了微生物测序数据的特殊距离,所介绍的聚类算法除了目前使用的方法之外,还可以被看作是分析微生物数据的一个很好的辅助工具。
研究人员指出,下一步会基于Dirichlet-Polyomial等模型进行分区,与文章中的方法进行比较,并努力将该方法扩展到其他微生物群落和疾病相关的数据上。
【参考文献】
Yang D, Xu W. Clustering on Human Microbiome Sequencing Data: A Distance-Based Unsupervised Learning Model. Microorganisms. 2020 Oct 20;8(10):E1612.