-

 国家认可委 CNAS L23010 认可项目:微生物宏基因组 | 16S rRNA扩增子
国家认可委 CNAS L23010 认可项目:微生物宏基因组 | 16S rRNA扩增子

 二级病原微生物安全实验室
二级病原微生物安全实验室 国家高新企业 | ISO9001认证 | 肠道健康精准检测高新技术研发中心 | 专精特新企业
国家高新企业 | ISO9001认证 | 肠道健康精准检测高新技术研发中心 | 专精特新企业- 联系电话:+13336028502
- +400-161-1580
- service@guheinfo.com
二级病原微生物安全实验室 国家高新企业 | ISO9001认证 | 肠道健康精准检测高新技术研发中心 | 专精特新企业

谷禾健康
如果你正为宏基因组数据的组装和注释而忙于“拼工具、调环境、转格式”,那么annoSnake或许能让你从繁琐中解放。
它是一个基于Snakemake的自动化工作流程,从clean reads组装到物种分类、功能注释,再到MAGs的装配和注释。
作为开源工具,annoSnake具备良好的可重复性、可扩展性和可移植性,非常适合HPC集群环境。
本文将带你了解它的工作流程、在白蚁肠道宏基因组数据上的验证结果,以及它的优势与局限,帮助你快速判断是否值得上手。
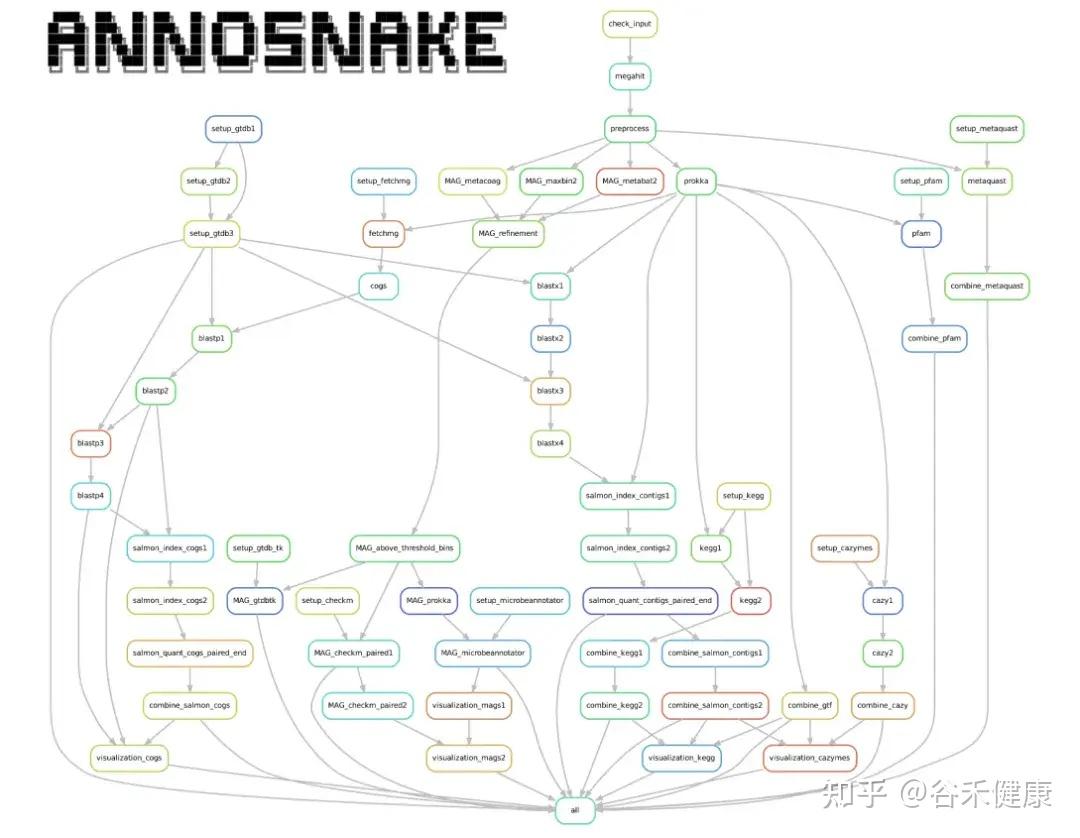
annoSnake以“自动化+模块化”为核心:输入clean reads → 组装 → 注释 → 分箱 → 结果汇总与可视化。
每个标准化步骤里,annoSnake使用的都是主流工具,如果你事先没有任何准备,也无需担心,它会自动创建独立的虚拟环境,并安装所需的分析工具和注释用的数据库。
分析前的准备
1. Mac OS或linux系统设备,磁盘空间推荐>100GB。如果运行单个宏基因组样本,只要有32 GB 内存和 8 核 CPU 基本就能跑完。
若要在集群上批量运行十几个样本或进行MAG分析,最好准备 ≥128 GB 内存和多核服务器。annoSnake 可批量化处理。
2. 安装mamba或conda用于管理环境,然后安装snakemake。
3.克隆Github仓库到本地(git clone https://github.com/bheimbu/annoSnake.git)。
4. 清洗后的测序数据,可以是双端,也可以是交错合并的fastq.gz文件,注意要是gzip格式。
5.编辑./profile/params.yaml和./profile/config.yaml文件。config.yaml 决定“要做什么”与“怎么做”,config.yaml 决定“在哪跑、分配多少资源”。
首次分析,annotSnake会自动下载并设置GTDB、dbCAN、Pfam、KEGG等数据库,总量约100GB。
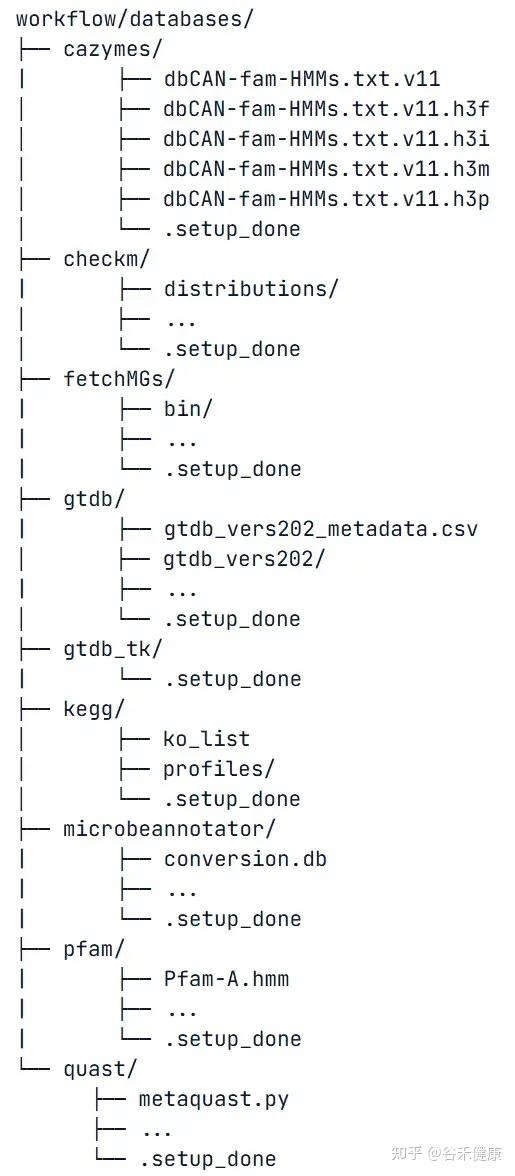
开始分析
1. 组装
MEGAHIT v1.2.9工具进行宏基因组组装,默认–presets meta-sensitive模式组装,保留≥1500 bp的contigs,并以metaQuast评估组装质量。
2. 物种分类注释
Prokka v1.14.6工具识别CDS、rRNA、tRNA;fetchMG v1.2提取40个单拷贝标记基因;结合GTDB(v202, (Parks et al.2022)数据库进行blastp和blastx注释;自定义R脚本gtdb_diamondlca.R进行LCA分类整合。
3. 功能注释
对细菌/古菌的contig执行注释,可以选择的功能数据库有:CAZy(dbCAN version 11)、Pfam(version 35)和KEGG。
针对Pfam搜索结果,可以自行借助在线工具HydDB进一步分类。针对KEGG结果,借助KofamScan工具重建以KEGG为基础的代谢通路。E-values阈值在params.yaml中设定。
4. 基因丰度量化与归一化
Salmon v1.10.2对CDS进行TPM定量,对于TPM>1的,予以保留,然后对剩余TPM做CLR对数转换(默认,log(TPM+0.65))。
5. 分箱与注释(可选)
同是采用三种分箱算法:MetaBAT v2.10.2、MetaCoAG v1.1.1、MaxBin v2.2.7,最后用metaWRAP v1.3的bin_refinement整合最优集合,CheckM 评估MAGs质量,默认阈值是完整性≥50%且污染≤10%。
对优质的MAGs使用GTDB-Tk v2.3.2进行物种分类(数据库v214),Prokka做基因预测,然后用MicrobeAnnotator进行功能注释,该工具使用DIAMOND和KofamScan,并以通路基因存在/缺失评估完整性。
6. 输出与可视化
输出包括CSV表格和ggplot2/plotly生成的PDF/HTML图表。
!
Tips
annoSnake已经内置了“KEGG条目(KO编号)→基因名称/通路名称”的映射表文件。如果你想重点关注某些特定的KEGG基因或通路(比如只看甲烷生成、乙酸生成或硫酸盐还原等),可以在/workflow/rules/scripts目录下,直接编辑这类映射文件,把你关心的KO编号及其基因名、通路名加入或调整。
管道运行时会按你改过的清单去批量检索与汇总这些目标基因/通路的注释与丰度,并在输出图表中优先呈现,从而实现“按课题定制”的结果视图。
作者用来自澳大利亚Amitermes组(AAG)的白蚁肠道宏基因组作为测试数据,与已知发现进行一致性检验。
▸在测序深度不高时仍能识别主要细菌谱系和代谢通路
31个群体,Illumina NextSeq双端,平均每样本约700万条reads。尽管测序深度不高,但annoSnake仍有效识别了主要的细菌谱系,以及大量与木质纤维素消化相关的代谢通路和基因。
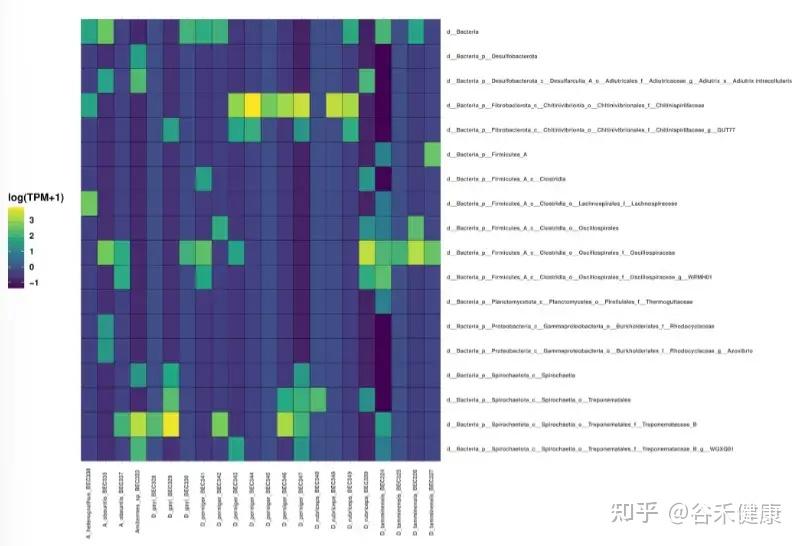
图中是annoSnake识别出的主要菌群,结果显示不同取食类型白蚁肠道的优势类群模式,这与已知发现相符,通常,食草和食木的白蚁其肠道群落以螺旋体为主,而食腐殖质和土壤的白蚁则富含梭菌(clostridia)。
但也有与已知发现不符的结果,D. tamminensis物种的肠道群落以梭菌为主,几乎不见螺旋体或Fibrobacterota,部分D. gayi群体也表现出类似模式,这与“草/木料取食类型的白蚁常以螺旋体占优”的普遍模式不一致,作者解释这是数据特性使然,低覆盖度数据只能恢复高丰度群落成员,而非物种生态学的结论。
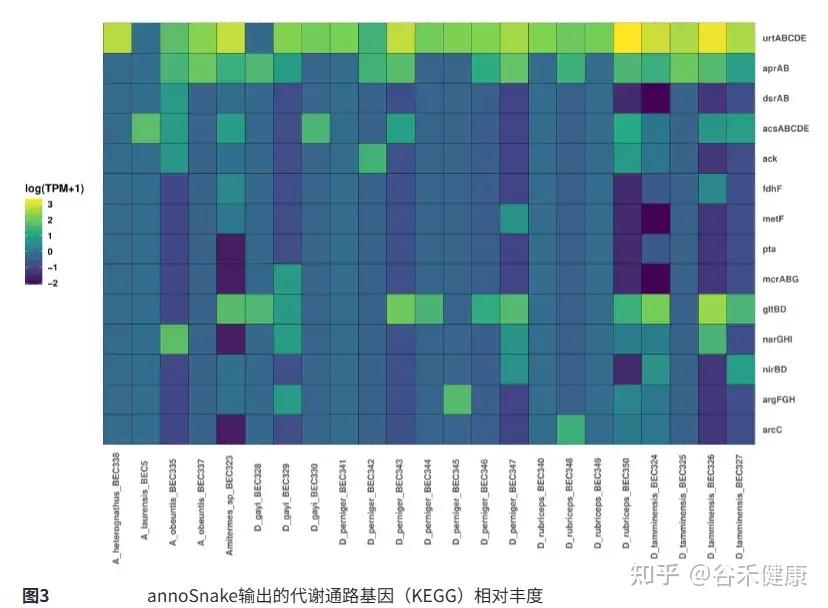
▸ 识别出硫酸盐还原等重要通路的基因
在所有样本中,annoSnake识别出硫酸盐还原通路的关键基因,如aprA、aprB和dsrAB,这符合白蚁肠道微生物组中硫酸盐还原过程的常见模式。还有许多与木质纤维素消化相关的KEGG代谢通路基因,这支持白蚁肠道微生物组在碳循环和能量代谢方面的普遍功能特征。
仅检测到少量与甲烷生成相关的基因,如mcrABG。已知甲烷生成主要局限于厌氧甲烷生成古菌,而本次分析中未有样本被检测到古菌,所以甲烷生成基因稀少是符合预期的。这与低覆盖度数据仅恢复高丰度群落成员的特性一致,古菌可能被低估,而不是KEGG注释的偏差。
识别出fdhF和acsABCDE等基因预测还原性乙酸生成的存在,这一点由分箱得到的15个Bacillota和6个螺旋体MAGs所支持,这两类群包含潜在的乙酸生成菌。这与其他白蚁和千足虫研究中已知的乙酸生成潜力一致。
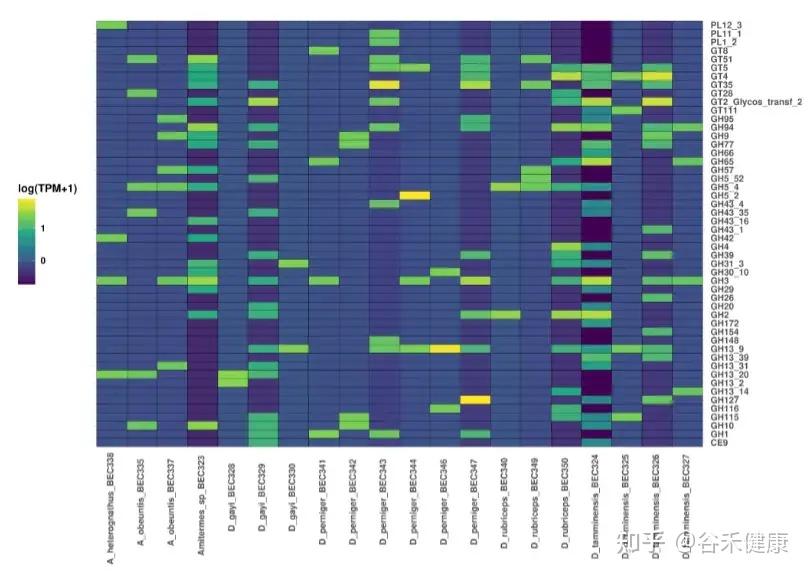
▸ 能够检测到大量碳水化合物活性酶
annoSnake检测到大量CAZymes(碳水化合物活性酶)。D. tamminensis在不同群体间的GHs丰度差异再次暗示饮食灵活性,且部分群体GHs模式与腐殖/土壤取食物种一致;螺旋体主导的D_gayi_BEC329中GHs丰富,符合凋落物取食物种的特性,而在梭菌主导的D. gayi群体中GHs较低。
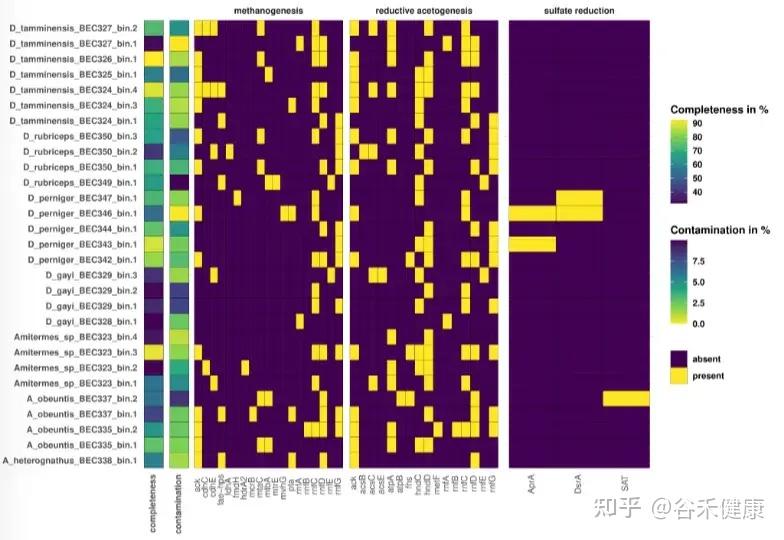
annoSnake从低覆盖度数据中获得30个MAGs,其中包括15个Bacillota(内含大量梭菌纲)、1个Desulfobacterota、7个Fibrobacterota、1个Pseudomonadota、6个Spirochaetota。
图中展示了MAGs中木质纤维素消化相关代谢途径(甲烷生成、还原性乙酸生成、硫酸盐还原)基因的存在/缺失。左侧给出MAG的完整性和污染分值,颜色越浅表示完整性越高,污染越少。 紫色方块表示基因缺失,黄色方块表示基因存在。
优势
• 覆盖全流程的一站式自动化:从输入reads→组装→物种注释→功能注释→丰度定量→分箱(可选)→可视化,节省操作时间。
• 数据库自动下载和配置。
• 兼具一些灵活性,比如可以自定义数据库,也能调整分析参数。
• 可重复、可扩展、可移植。Snakemake内核+HPC优化,可以在不同HPC环境中高效执行。
劣势
• 资源占用较高,数据库体量约100GB,完整流程在大规模数据上更适合HPC环境;本地轻量设备可能受限于存储、内存与时长。
• 需要有一定代码基础,掌握Snakemake、Conda与YAML配置,能调试环境配置时可能出现的错误。
• 范围聚焦细菌/古菌,真核生物未被纳入默认流程,氢化酶精细亚型分类需借助HydDB等外部工具,未在管道集成。
• 低覆盖度数据的固有限制:对稀有类群的恢复能力受限,更偏向于恢复高丰度成员,需要结合研究设计与深度规划权衡。但作者也没有发表对高覆盖度数据的测试结果,所以工具对高覆盖度数据的表现不明确。
• 工具较新,容易出现环境/兼容性问题或边缘情况未覆盖;第三方依赖更新也可能引入不稳定性。数据库管理灵活性受限,版本固定且无更新管道。虽支持自定义数据库,但需自行调整文件格式。
o 输出的图像不够美观,可视化类型单一。
annoSnake适合具备中级生信技能,需快速产出的微生物组学研究者。如样本量大,需批量分析,则需要配备高性能设备。研究范围在细菌/古菌的宏基因组与MAGs。
下面这个网址可访问 annoSnake 文档:
https://annosnake.readthedocs.io/en/latest/index.html
参考文献:
Bastian Heimburger, Rebecca Clement, Tamara R. Hartke
bioRxiv 2025.11.03.686227; doi: https://doi.org/10.1101/2025.11