 国家高新企业 | ISO9001认证
国家高新企业 | ISO9001认证 二级病原微生物安全实验室
二级病原微生物安全实验室- 联系电话:+13336028502
- +400-161-1580
- service@guheinfo.com
国家高新企业 | ISO9001认证 二级病原微生物安全实验室
谷禾健康
宏基因组中短序列的注释是理解测序微生物群落潜在功能的重要步骤之一。单纯利用局部匹配的注释容易混淆那些蛋白同源性且局部序列非常相似的序列,进而不能真实准确反映复杂蛋白质家族中多变的结构和功能域。

今天我们介绍一种新方法MetaGeneHunt,该方法可以识别特定的蛋白质结构域,并根据结构域的长度对hit-counts进行标准化。使用MetaGeneHunt对MG-RAST对公开获取的宏基因组进行分析,包括哺乳动物微生物群和Twin Gut肠道菌群研究,以评估短序列中含GH蛋白的频率和位于GH区域的匹配频率。
在对糖苷水解酶(GHs)的研究,发现在所有样本中4726,023条含有GH区域蛋白匹配的短读序列中,有58.3%的序列位于目标区域之外。接下来,在比较样本之前,将匹配到目标区域的hit-counts标准化,以说明对应的域长度。肠道和盲肠中的菌群显示出与不同微生物组合相匹配的GH谱特征。
相反,胃和结肠的菌群在结构和功能上显示出更多样性和多变性。在样本中,尽管有波动,但碳水化合物处理的潜在功能变化与群落组成的变化相关。这表示,在利用MG-RAST平台处理宏基因组测序序列时,MetaGeneHunt是一种能快速准确地识别短序列宏基因组中离散蛋白结构域的新方法。
在过去的几十年里,宏基因组DNA的高通量测序已经产生了大量的序列,这些序列的特征为我们了解微生物群落的结构和功能提供了许多认知。例如,截至2019年12月,MG-RAST托管了约40万个可公开访问的带注释的数据集。在数据处理过程中,不考虑目标区域(或蛋白质)的长度会导致两个主要的系统偏差。
首先,目标区域越长,他们的频率就越容易被高估。其次,如果数据处理涉及稀疏性,较短的、不太丰富的域,尽管重要,也可能被丢弃。为了解决这些问题,研究人员设计了MetaGeneHunt来精确注释从MG-RAST检索到的短序列宏基因组中的蛋白质结构域。MetaGeneHunt将MG-RAST提供的短序列局部比对与M5nr数据库中精确的基于PFam的蛋白质结构域识别相结合,以在公共可访问数据集中识别蛋白质结构域。
MetaGeneHunt简要说明:
MetaGeneHunt的设计基于MG-RAST平台注释的数据集的。在使用GeneHunt创建的M5nr数据库中,MetaGeneHunt使用了糖苷水解酶和辅助结构域(如CBMs)的精确的特定结构域注释(PFam)作为参考注释表(RAT)。
首先,MetaGeneHunt使用MG-RAST应用程序接口从MG-RAST(“330”和“650”文件)检索M5nr注释的宏基因组。接下来,使用来自RAT的注释命中的MD5id,在文件“650”中识别与潜在的GHs匹配的序列。
接下来,对于这些局部匹配,将精确对齐位置与RAT中特定于域的注释进行比较。如果查询中的>20AAs与特定的蛋白质结构域(考虑到RAT中的HMM-envelope位置)对齐,则该结构域注释被转移到查询中。
相反,如果查询的>20AAs匹配在目标区域之外(例如,在连接域、辅助域、信号肽中),则该注释被认为是否定的。用户可以随意修改重叠(overlapping)的阈值。接下来,从序列聚集文件( “330”文件)中检索每个识别出的命中的实际序列计数。最后,在后续的数据处理和标准化过程中,根据Pfam数据库中蛋白质结构域的大小,对每个蛋白质结构域的命中计数进行标准化。
方法验证:
文中使用的原始数据和预处理数据可在MG-RAST服务器上公开访问。在mgp20861项目中可获得对应于〜555百万个100 bp序列的小鼠微生物组数据。使用MG-RAST API 检索了哺乳动物微生物组数据(mgp116)和双肠肠道菌群研究(mgp10)其他数据集。哺乳动物微生物组研究糖苷水解酶(GHs)和相关酶的附加注释表是从Brian Muegge(直接对应)获得的。使用MG-RAST API检索了预处理的数据,包括从门到属水平的读物分类注释。数据分析和统计使用R统计语言。
1. 糖苷水解酶的识别,识别蛋白质结构域并考虑其长度产生了一个健壮的功能注释系统,对hit-count的标准化反应了目标区域的实际分布。

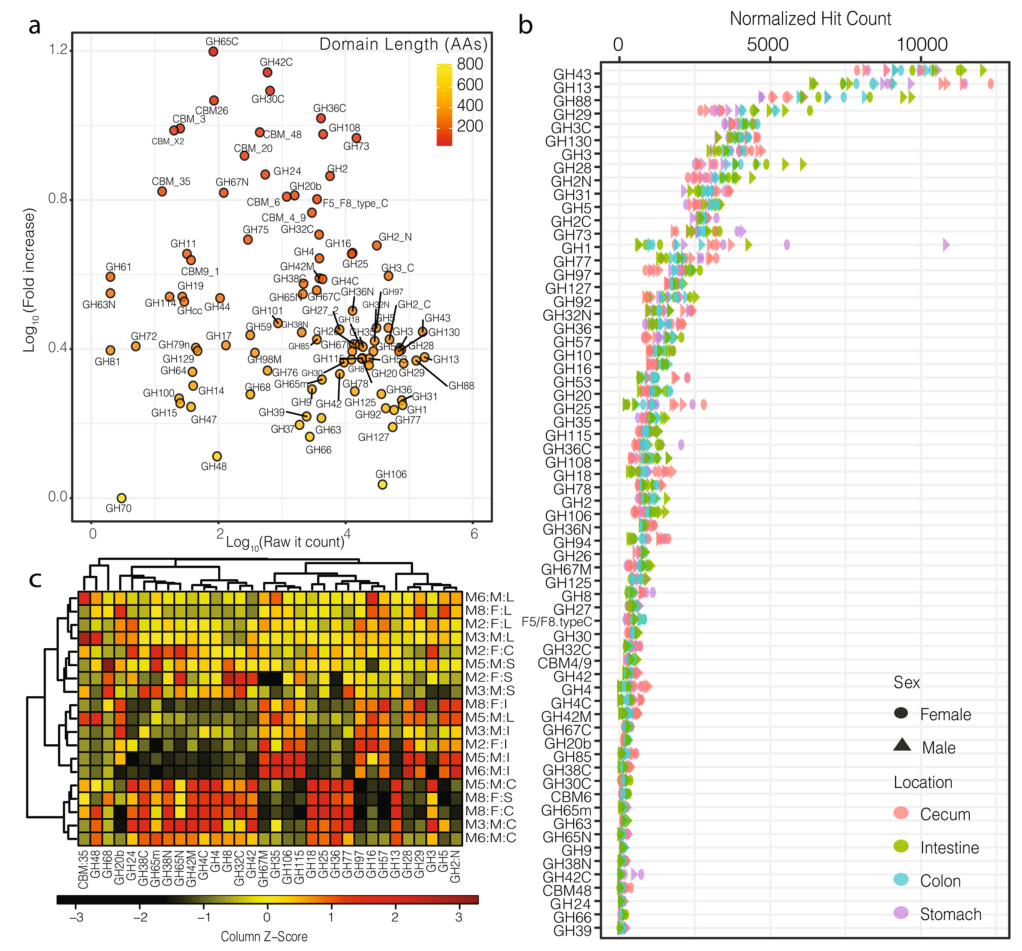
a).横轴为目标区域的原始hit-count,纵轴为标准化后的hit-count,图中的颜色阶梯表示目标区域的长度。这种标准化主要影响长度短的域(例如,GH78、GH25)、小的亚域(例如,GH31N、GH36C)和目标区域的附属域(例如,CMB5_12)。
b).小鼠胃肠道中目标区域的标准化后的hit-count(仅显示大于100的hit-count的区域),可见,标准化后的hit-count与结构域长度无关(附加文件中有对两者做相关分析,结果分别为P.pearson=0.38,P.spearman=0.33)
c).热图显示了小鼠胃肠道中最受样本来源影响的被稀疏标准化的GH区域的分布(two-way方差分析)。纵轴的注释列Mx:F/M:S/I/C/L分别表示小鼠(样本号):雌性/雄性:胃/肠/盲肠/结肠
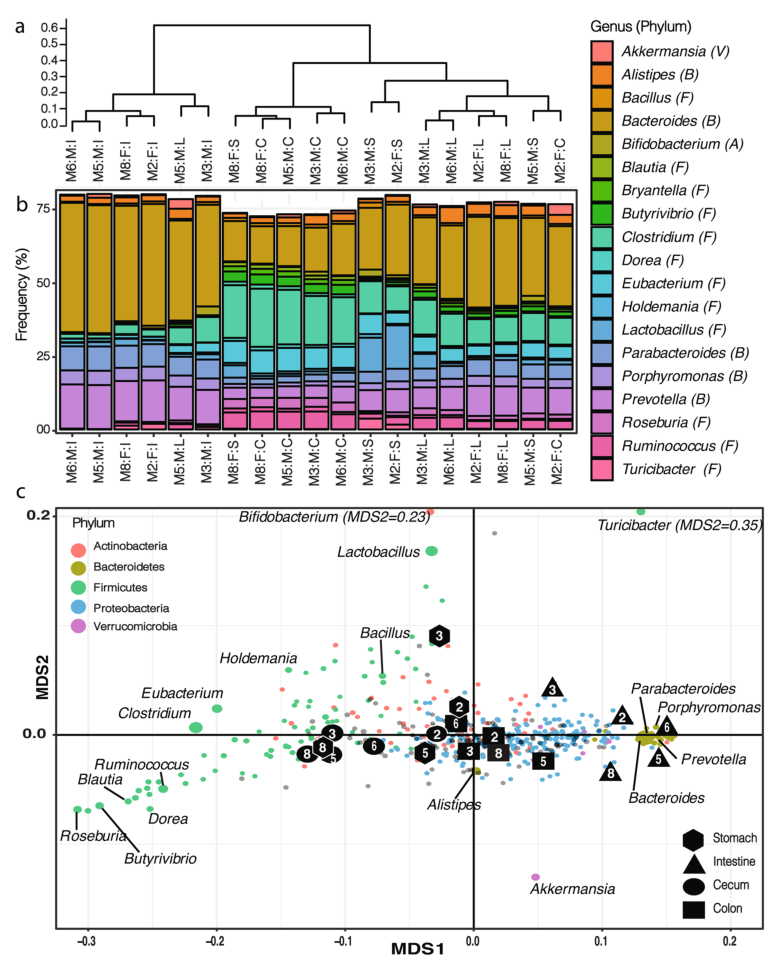
2. 小鼠肠道菌群的结构,与盲肠中的微生物群落相比,结肠与肠道中的微生物群落结构更相似,结肠和胃中的微生物群落有较高的相似性。

a).对受样本来源影响较大的样本根据属水平进行样本聚类(Bray-Curtis距离指数,complete linkage)。
b).样本间的微生物群落组成,只展示了相对丰度至少占群落中1%的属水平物种(V:疣微菌门,B:拟杆菌门,A:放线菌门,F:厚壁菌门)。
c).NMDS分析(2D stress=0.020),展示了在样本聚类中都存在的这些菌属,在b)中的主要类群用标签指示,不同门水平按颜色区分,点的大小反映该属在样本中的最大频率。
微生物组中的结构-功能关系,多样性仍然与潜在功能高度相关。胃和盲肠的群落在结构和功能上是最多样化的。其次,肠道中的群落组成和功能大多是保守的,而与保守的微生物群落相关的大肠则显示出可变功能潜力。
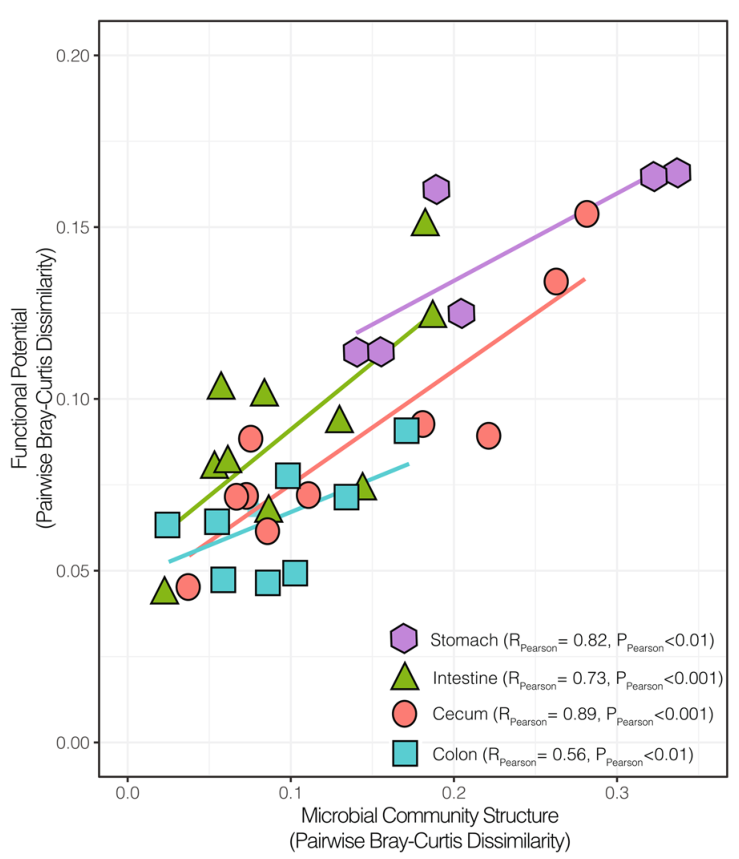

对同一位置的样本的微生物群落结构和功能差异进行成对比较(Bray-Curtis),线条为线性回归的结果。在胃,肠,盲肠和结肠中,属水平群落结构的变化与多糖解构功能的相关性分析结果表示除大肠外,其余的P.pearson的值都在0.001以下。胃和盲肠的群落在结构和功能上是最多样化的,尽管多样性仍然与功能潜力高度相关。其次,肠道中的群落组成和功能大多是保守的,而与保守的微生物群落相关的大肠则显示出可变的功能潜力。
MetaGeneHune提供了一种新的方法来识别短序列宏基因组中的GHs及其相关结构域。识别结构域而不是蛋白质是至关重要的,因为GH结构域与许多可变结构域相关。这种新方法基于GeneHunt注释方法,并对其进行补充,旨在分析MG-RAST中的短序列宏基因组。因此,它不需要大型计算机基础设施。
通过这种新方法对小鼠胃肠道菌群的GHs研究发现,在胃中,虽然富含碳水化合物处理的酶,但相对于胃肠道的其他部分,胃中没有特定酶可供选择;在肠道中,出现了更保守的菌群,最为富集的是拟杆菌门,它们的潜在功能主要在多糖处理上;来自结肠和胃的菌群虽然是距离最远的,但在结构和功能上却表现出高度的相似性。
在未来,利用GeneHunt和MetaGeneHunt相结合创建新的专用参考注释表将为研究宏基因组的潜在功能提供新的更有效的途径。
MetaGeneHunt和GH的RAT可在GitHub上公开访问。(https://github.com/renober/MetaGeneHunt)
参 考 文 献
Berlemont R, Winans N, Talamantes D, Dang H, Tsai HW.MetaGeneHunt for protein domain annotation in short-read metagenomes. Sci Rep.2020 May 7;10(1):7712. doi: 10.1038/s41598-020-63775-1. PMID: 32382098; PMCID:PMC7205989.
Muegge BD, et al. Diet drives convergence in gut microbiomefunctions across mammalian phylogeny and within humans. Science.2011;332:970–4. doi: 10.1126/science.1198719
Turnbaugh PJ, et al. A core gut microbiome in obese and leantwins. Nature. 2009;457:480–484. doi: 10.1038/nature07540.
Berlemont R, Martiny AC. Glycoside Hydrolases acrossEnvironmental Microbial Communities. PLOS Comput. Biol. 2016;12:e1005300. doi:10.1371/journal.pcbi.1005300.
Lozupone CA, Stombaugh JI, Gordon JI, Jansson JK, Knight R. Diversity,stability and resilience of the human gut microbiota. Nature. 2012;489:220–30.doi: 10.1038/nature11550.
Sharpton TJ. An introduction to the analysis of shotgunmetagenomic data. Front. Plant Sci. 2014;5:209. doi: 10.3389/fpls.2014.00209.

谷禾健康
链读测序(Linked-read sequencing)通过将相同的barcode与长DNA片段(10-100kb)的序列连接在一起,能够消除其中的一些错读,从而改进宏基因组组装。但目前还不清楚在使用链读测序时参数的选择对组装的质量的影响如何。
近日,香港浸会大学研究人员发表文章 “通过链读测序对宏基因组组装全面研究”。


模拟数据和模拟菌群中的分析结果表明,模拟数据(simulated data)中读取深度(C)与组装序列的长度呈正相关,但对组装序列的质量影响不大,模拟菌群的研究中读取深度(C) 对组装序列的质量以及被注释为基因组草图的bin的比例有轻微影响。
另一方面,宏基因组组装质量受CR(每个短读长片段的平均深度)和CF(由长DNA片段计算的基因组的平均物理深度)的影响。对于相同的读取深度,较深的CR 会产生更多的基因组草图,而较深的CF 会提高基因组草图的质量。
还发现μFL(未加权的DNA片段的平均长度)对组装有边际效应,而NF/P(每个分区的片段数)对局部组装涉及到的偏离目标读数(off-target reads)有影响,即较低的NF/P值会通过减少off-target序列的错读而有更好的组装效果。
总体而言,与Illumina的短读长相比,使用链读改善了组装中重叠群的N50,但与PacBio CCS的长读长相比则没有改善。
人体微生物群是一个复杂的系统,在生理活动和疾病中起着重要的作用。对微生物群中的微生物基因组进行测序可以帮助我们研究其功能。
然而,微生物基因组序列很难获得,微生物群中的绝大多数微生物不能被分离出来进行单个测序。目前的宏基因组项目中使用短读长测序对混合的微生物基因组进行测序。
这些结果在基因组组装过程中是有错读的,导致微生物基因组的完整性和重叠群的连续性结果不理想。长读长测序已经被用来尝试减轻这些问题,如Nicholls等人和Sevim等人的研究。特别是Moss等人的研究,其成果优化了纳米孔测序的长读长文库制备方案,并获得了更完整的细菌基因组。
但实际应用中,长读长测序是昂贵的。虽然链读序列(linked-reads)的基因组组装的质量无法与PacBio CCS的长读长相提并论,但其低成本和高碱基质量的优点是值得去使用的。
01 三组链读序列数据集的来源及构成:
模拟数据(simulated data):
从MBARC-26数据集中下载了23个细菌和3个古细菌菌株,按丰度分类,L-sim,低丰度微生物,摩尔浓度<10-15;M-sim,中等丰度微生物,10-15 < 摩尔浓度 < 10-14;H-sim,高丰度微生物,摩尔浓度 > 10-14
模拟菌群(mock community):
(ATCC MSA-1003)是一个由20个菌株组成的池,同样按丰度分类,L-mock,低丰度微生物;M-mock,中等丰度微生物;H-mock,高丰度微生物;UH-mock,超高丰度微生物。
人类肠道菌群:
一份来自健康的中国人粪便样本
02 DNA提取、文库制备和测序:
对于模拟菌群,从ATCC 20菌株交错的混合基因组材料中提取DNA,不进行大小选择。
对于人类肠道菌群,用Qiagen QiAaMP粪便迷你试剂盒提取DNA,去掉5kb以下的DNA片段。
脉冲场凝胶电泳后,按照厂商的说明制备10x Chromium文库。使用Illumina XTen双端2x150bp测序。人类肠道微生物组的DNA也被用于标准的Illumina XTen短序列测序。
03 DNA长片段重建和链读序列二次抽样:
Long Ranger v2.2.1用于纠正barcode碱基错误,计算PCR重复率,并完成barcode感知的链读序列比对。
使用BWA-MEM v0.7.17比对短序列和没有barcode的链读序列。根据映射得到的具有共同的barcode的短序列的坐标重建DNA长片段。
链接序列首先按barcode排序,然后按它们的映射坐标排序。如果最近的barcode序列大于50kb,则终止延伸长DNA片段。每个片段必须包括至少两个具有共同barcode的成对序列,并且最小长度为2kb。
04 宏基因组组装:
对于链读序列的组装,没有 barcode 的链读序列首先由 metaSPAdes v3.11.1使用默认参数组装为“seed”重叠群,并通过BWA-MEM v0.7.17与重叠群比对。
最后使用 Athena-meta v1.3 通过汇集在 scaffold 中的两个“seed”重叠群里共享相同 barcode 的序列进行局部组装。
05 组装效果评估:
MaxBin v2.2.4将长于1kb的重叠群分组到bins中,并通过CheckM v1.0.12评估其完整性和污染率。
Quast v5.0.0统计了基础信息,如重叠群的N50、NG50、NGA50、总比对长度(total aligned length)和基因组覆盖率(genomic coverage)。
Kraken v0.10.6基于内置数据库MiniKrakenDB为bins做物种注释。每个bins都作为一个基因组草图,被分类为高质量的(完整性>90%,污染率<5%),中等质量的(完整性≥50%,污染率<10%),低质量的(完整性<50%,污染率<10%)
来自人类肠道菌群和Illumina短序列链读序列二次抽样的组装效果统计
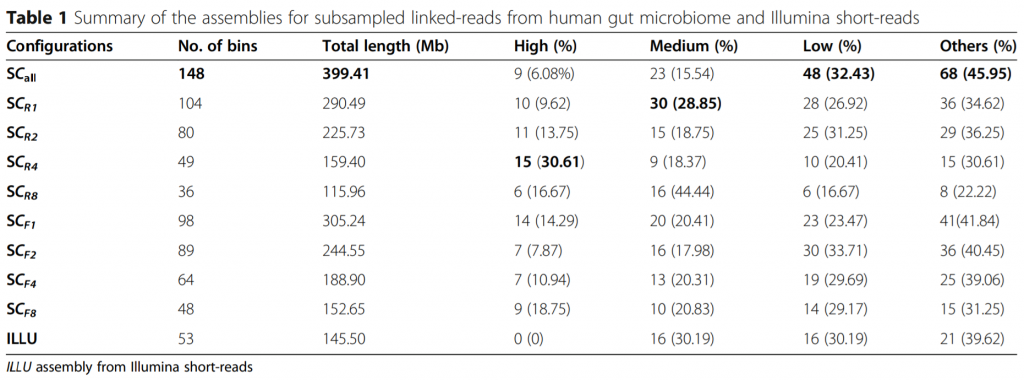

ILLU,Illumina短序列的组装
SC-all,模拟菌群和人类肠道菌群总共的两个测序lane链读序列
在链读测序中,有四个关键参数可能会影响宏基因组组装,如下图。
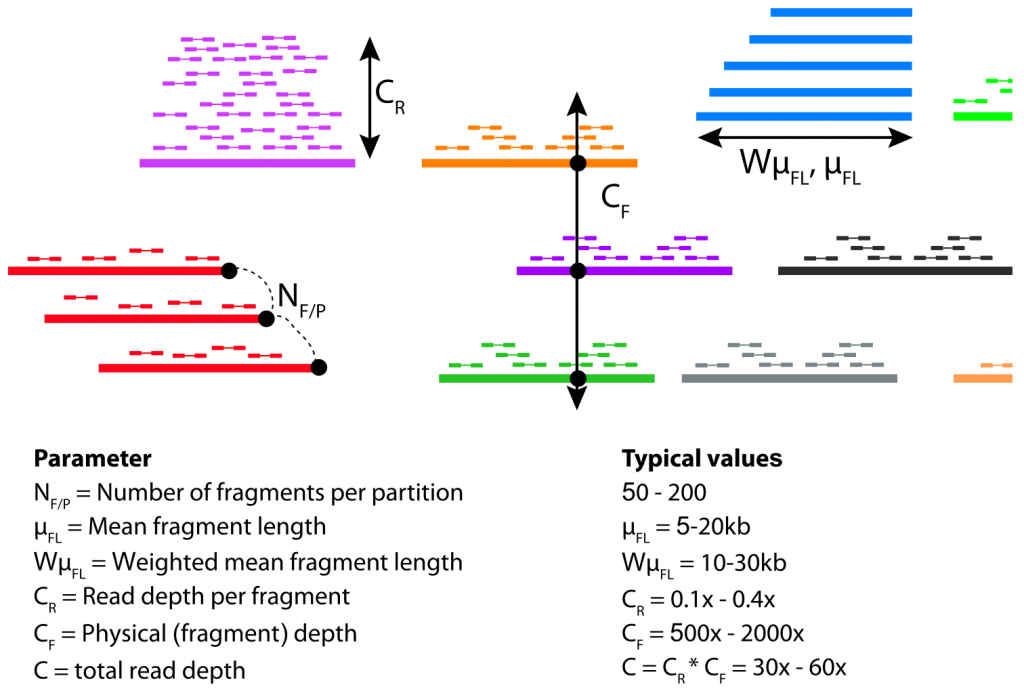

这些参数中有几个是相互依赖的。例如,输入DNA的量越大,CF和NF/P都会增加,CR就会降低;CF和CR的绝对值是由总读取深度(C)增加多少来设置的,因为CR×CF=C。
L-sim,模拟数据中的低丰度微生物,青色
M-sim,模拟数据中的中等丰度微生物,蓝色
H-sim,模拟数据中的高丰度微生物,红色
L-mock,模拟菌群中的低丰度微生物
M-mock,模拟菌群中的中等丰度微生物
H-mock,模拟菌群中的高丰度微生物
UH-mock,模拟菌群中的超高丰度微生物
“-”表示测序lane的倒数,例如MSCR4/MSCF4表示四分之一测序lane的序列被二次采样
MSCR-,模拟菌群中的短序列
MSCF-,模拟菌群中的长DNA片段
MSC-1,模拟菌群和人类肠道菌群总共的一个测序lane链读序列
SC-all,模拟菌群和人类肠道菌群总共的两个测序lane链读序列
相关阅读:
参考文献:
Zhang L, Fang X, Liao H, Zhang Z, Zhou X, Han L, Chen Y, Qiu Q, Li SC. A comprehensive investigation of metagenome assembly by linked-read sequencing. Microbiome. 2020 Nov 11;8(1):156. doi: 10.1186/s40168-020-00929-3. PMID: 33176883; PMCID: PMC7659138.
He S, Chandler M, Varani AM, Hickman AB, Dekker JP, Dyda F: Mechanisms of evolution in high-consequence drug resistance plasmids. MBio 2016;7(6): e01987–16.
Peng Y, Leung HC, Yiu SM, Chin FY. IDBA-UD: a de novo assembler for single-cell and metagenomic sequencing data with highly uneven depth.Bioinformatics. 2012;28(11):1420–8.
Li D, Liu CM, Luo R, Sadakane K, Lam TW. MEGAHIT: an ultra-fast singlenode solution for large and complex metagenomics assembly via succinct de Bruijn graph. Bioinformatics. 2015;31(10):1674–6.
Nurk S, Meleshko D, Korobeynikov A. Pevzner PA: metaSPAdes: a new versatile metagenomic assembler. Genome Res. 2017;27(5):824–34.
Nicholls SM, Quick JC, Tang S, Loman NJ. Ultra-deep, long-read nanopore sequencing of mock microbial community standards. Gigascience. 2019;8(5): 1–9.
Sevim V, Lee J, Egan R, Clum A, Hundley H, Lee J, Everroad RC, Detweiler AM, Bebout BM, Pett-Ridge J, et al. Shotgun metagenome data of a defined mock community using Oxford Nanopore, PacBio and Illumina technologies. Sci Data. 2019;6(1):285.

谷禾健康


在现代测序技术的帮助下,微生物组研究的范围被扩大,通过16S rRNA测序或鸟枪法宏基因组测序可以生成大量的微生物组数据。而微生物群落研究中的一个重要问题是对这些微生物的归类,模拟和分析人类微生物群。
通常使用16S rRNA技术量化微生物群落的组成,但量化后的数据是偏斜的,带有过多的0。目前还缺乏对复杂的微生物群落测序数据的标准化的聚类分析方法。
近日,加拿大多伦多大学研究人员在《Microorganisms》上发表的一篇研究,针对上述问题构建了一个参数化的混合模型用于计算聚类分析的距离度量,模型根据观察到的OTU计数和估计的混合权重产生sample-specific的分布。这个方法可以准确的估计真实的0比例,从而构建一个精确的beta多样性度量。
大量的模拟研究表明,与一些被广泛使用的距离度量方法相比,当存在较大比例的0时,该方法取得了较好的聚类效果。
该研究人员提出了一种具有特定beta多样性度量的聚类算法,该算法可以解决稀疏计数数据遇到的有无偏差问题且能有效的度量样本距离,达到分层的目的。
微生物群落研究中的一个重要问题是对这些微生物的归类,它们是否能被划分为亚群。如果有,有多少组亚群,如何解释这个亚群。例如,这种分类是否区分了治疗方法、疾病或遗传类型。
为了回答这些问题,需要测量两个微生物群落之间的相似性。beta多样性是为了适应不同的目的而提出的,在评估群落之间的差异时提供不同的结果。对于微生物组成,beta多样性根据测量丰度来衡量群落之间的距离,丰度可以是观察到的计数,也可以是相对丰度,这些丰度是根据不同或距离度量计算出来的,以量化样本之间的相似性。
现如今,已经有许多非参数统计方法来量化距离度量。例如Euclidean和Manhattan距离是最常用的。其它beta多样性指标,例如Bray-Curtis距离、Jensen-Shannon距离、Jaccard指数、UniFrac距离(未加权的、加权的和广义的)也经常用于微生物组研究。
除了距离度量之外,还引入了用于生态关联推理的稀疏逆协方差估计(SPICE-EASI)的图形网络模型。然而这些方法都会有一定的局限性,例如SPIEC-EASI方法依赖于单一的方差-协方差矩阵,由于微生物群落结构复杂,可能无法完全恢复底层OTU网络。
于是,研究人员开发了一种创新的聚类方法,以混合模型而不是beta多样性度量作为距离度量,并将聚类算法应用于微生物群落数据来表征亚群。该算法还包括根据选择的内部指标选择最优聚类数,并将结果在几种距离度量和不同评估方法之间进行比较。通过全面的模拟研究和一个真实的帕金森病肠道微生物群数据集对该算法的性能进行了评估。
1. 构建混合模型
混合模型是一种概率模型,用于表示在无监督学习中经常使用的总体内的子群体。该模型关注单个OTU在种群中的分布,可以解决样本间的稀疏性问题。它参数化地模拟了计数的潜在分布,包括低计数OTU和极高计数。对于个体样本之间的成对距离,在L2范数距离中使用公式化的混合概率。
2. 距离度量
在确定混合模型分布后,使用概率分布通过样本之间的两两距离计算距离度量。为了进行比较,考虑了基于L2范数的三种距离度量(L2-PDF、L2CDF、L2-DCDF、L2-CCDF)。
除此之外还选择了一些其他的距离度量进行比较,即Manhattan距离和Euclidean距离,以及微生物组分析中特有的三个距离度量:Bray-Curtis距离、加权UniFrac距离和广义UniFrac距离。本研究不考虑未加权的UniFrac距离,因为它不包含类群丰度信息。
3. 聚类分析验证指数
这些指数用于衡量集群在集群内部和集群之间的可分离性表现很好。验证指标可以分为内部指标和外部评估,许多内部验证指标被用来选择最优聚类数。外部评估分数是在假设标签在建模阶段没有使用时,通过直接将划分结果与之前的标签进行比较来计算的。
4. 用于聚类的分区算法(PAM)

使用混合分布的聚类过程的详细步骤:
为了测试该方法在聚类中的表现如何,研究人员推导了其准确性和Jaccard指数。
准确性是指聚类结果与真实的聚类指数的接近程度。它被定义为正确聚集的受试者所占的比例。
Jaccard指数衡量聚类结果与原始聚类标签之间的相似性,原始聚类标签定义为正确分类的主题数量(预测集与真实集的交集 )与两组总样本量(两集的并集)之比。
研究人员用类标签模拟数据来模拟OTU计数及其复杂的结构。研究人员考虑两个有两个子类和三个子类的场景,每个子类包含200个样本,总样本量分别为400和600。所有的结果被重复了100次。
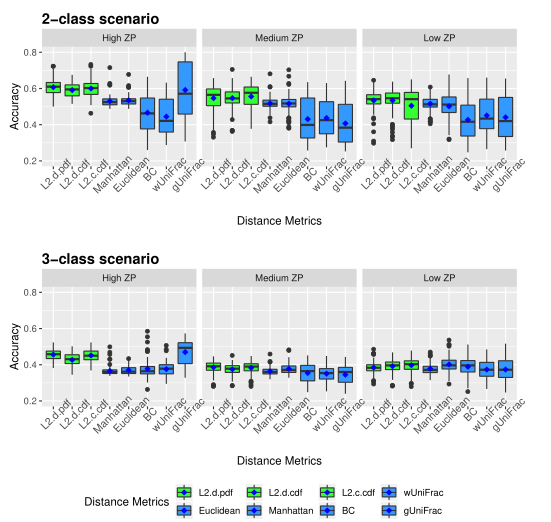
下图展示了模拟数据的准确性。评估了三种不同的0的比例(ZP)情况,左中右分别为高ZP、中等ZP、低ZP。
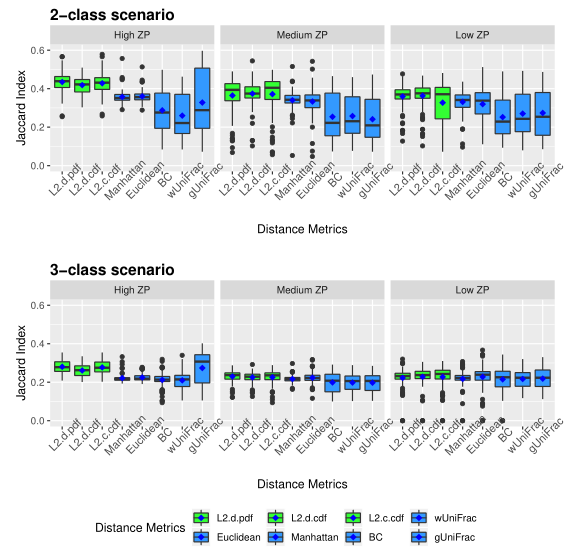
下图展示了模拟数据的Jaccard指数。同上图一样评估了三种不同的0的比例。
以上两图显示了具有不同ZP和子类数量的不同场景下模拟数据集的聚类结果。通过准确率和Jaccard指数对基于距离的算法性能进行了评估。填充颜色为绿色的箱形图为研究人员建议使用的距离度量。所有的距离都是根据相对丰度计算的。
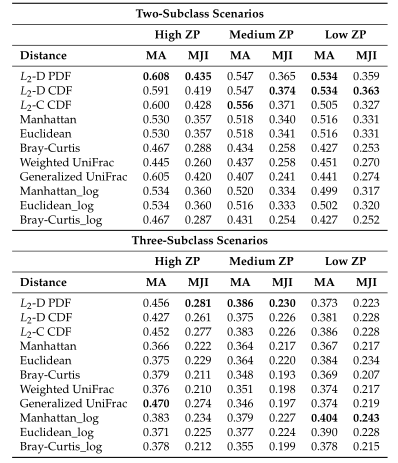
Table1平均准确率(MA)和平均Jaccard指数(MJI)估计。粗体表示每个方案下的最佳情况。Log表示对输入的模拟数据进行了对数变换。
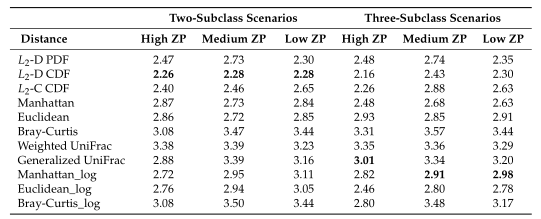
Table2所有模拟场景的平均集群数。根据Dunn内部指数计算出每次重复的最优聚类数。
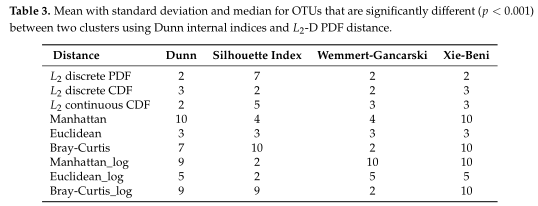
Table1 的结果是通过对每个场景中的100个重复结果求平均值计算得出的。观察得到在聚类算法中实现的距离度量(即绿色标识的箱形图)的准确率和Jaccard指数都优于其他距离度量,特别是在数据集中包含大量0时(高ZP)。在MA和MJI方面,L2范数也显示了其优势,在基于100次重复计算的L2范数在两个子类场景下的;平均准确率约为0.6秒,在三个子类场景下的平均准确率为0.45。而广义Unifrac距离(gUniFrac)在准确性估计中有很大的波动变化。
数据集为197名PD患者和130名对照的粪便样本的16S rRNA测序数据。首先过滤掉在80%的OTU中相对丰度都为0的OTU,因此,此次分析中共使用280个OTUs。将基于相对丰度计算的L2范数与其他三个距离度量进行了比较,包括对数变换和不变换的比较。
如Table3所示,距离度量采用各种内部验证指标(列名)进行灵敏度分析。对于Dunn和Xie-Beni指数,l2范数倾向于将数据聚类为两到三个亚群,而在有和没有对数变换的情况下,除了未变换的欧氏距离外,Manhattan、Euclidean和Bray-Curtis更倾向于聚类更多的亚群。(设置了最多聚类数目为10)
接着选择L2-D PDF范数作为进一步分析的例子。
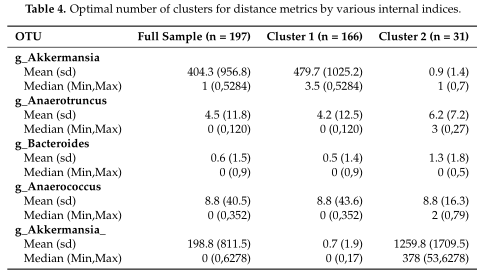
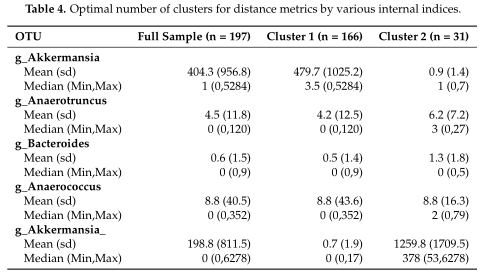
结果在Table4中展示,对数据集中的两个集群之间的OTUs进行了探索,得到了聚类之间差异最大的前5个OTU。
研究认为该聚类算法在高ZP和中等ZP的情况下表现最好,因此,当数据中出现大量的0时,建议使用。并且,在PAM框架下,文章中列出的那些距离度量都可以用作聚类的输入。
如模拟研究中显示的那样,在各种场景下,由混合模型计算的成对距离比其他距离度量表现的更好。但是与所有聚类方法一样,都有一个局限性,就是很难为每个新数据选择合适的内部指标,因此很难获得最优和最稳健的集群数。
此外,对于L2范数距离,在聚类中无法进行变量选择。但不可否认,该聚类算法结合了微生物测序数据的特殊距离,所介绍的聚类算法除了目前使用的方法之外,还可以被看作是分析微生物数据的一个很好的辅助工具。
研究人员指出,下一步会基于Dirichlet-Polyomial等模型进行分区,与文章中的方法进行比较,并努力将该方法扩展到其他微生物群落和疾病相关的数据上。
【参考文献】
Yang D, Xu W. Clustering on Human Microbiome Sequencing Data: A Distance-Based Unsupervised Learning Model. Microorganisms. 2020 Oct 20;8(10):E1612.