国家高新企业 | ISO9001认证
国家高新企业 | ISO9001认证 二级病原微生物安全实验室
二级病原微生物安全实验室- 联系电话:+13336028502
- +400-161-1580
- service@guheinfo.com
国家高新企业 | ISO9001认证 二级病原微生物安全实验室

谷禾健康
微生物组学研究现已超越微生物群落组成分析得到更广泛的使用。大量的人类微生物组研究证据表明,肠道微生物组的功能变化对炎症和免疫反应的影响起到关键的影响作用。
16S rRNA分析是微生物组研究作为最常用便捷且具有成本效益的测量技术,用于分析微生物组的菌落组成,但标记基因测序无法直接提供群落功能组成的信息。于是开发了生物信息学工具,利用16S rRNA基因数据来预测微生物组功能。
其中,PICRUSt2已成为最流行的功能概况预测工具之一,可生成整个群落通路丰度。“功能”通常指的是基因家族,如KEGG同源基因和酶分类号,可以预测任意的特性。
“
PICRUSt1 具有一定的局限性
微生物群落标记基因测序的一个局限性在于它无法提供有关采样群落功能组成的信息。PICRUSt1于2013年开发,可根据标记基因测序图谱预测细菌群落的功能潜力。
PICRUSt (Phylogenetic Investigation of Communities by Reconstruction of Unobserved States) 的原理基于已测细菌基因组的16S rRNA全长序列,推断它们的共同祖先的基因(同源基因)功能谱,对Greengenes数据库中其它未测物种的基因功能谱进行推断,构建古菌和细菌域全谱系的基因功能预测谱,最后,将测序得到的菌群组成“映射”到数据库中,对菌群代谢功能进行预测。
PICRUSt1是为从16S标记序列预测功能而开发的,已被广泛使用,但有一定的局限性。标准PICRUSt1工作流程要求输入序列只能根据Greengenes数据库的兼容版本进行有参比对而生成的OTU表。PICRUSt1使用的细菌参考数据库自2013年以来未进行更新,并且缺少成千上万个最近添加的基因家族。
“
PICRUSt2 具有更准确更全的数据库
2018年推出了全新版本的PICRUSt,即PICRUSt2(https://github.com/picrust/picrust2) ,该方法在PICRUSt1原始方法上有所改进。
具体而言, PICRUSt2包含一个更新的,更大的基因家族和参考基因组数据库,可与任何可操作的分类单位(OTU)筛选或去噪算法互操作,并能够进行表型预测。
基准测试表明,PICRUSt2比PICRUSt和其他竞争方法总体上更准确。PICRUSt2还允许添加自定义参考数据库。
PICRUSt1流程将预测限制为Greengenes参考数据库中的OTU,因此排除了其他16S rRNA基因测序数据集中的许多公开序列。PICRUSt2无需再以GreenGene注释的OTU表为输入,可以直接读取OTU的代表序列自动完成物种注释,并进一步根据物种丰度组成预测群落功能。
•用于预测的参考基因组数据库扩大了10倍以上。
•允许输出MetaCyc 本体预测,可与普通宏基因组学的结果比较。
•从Castor R包中添加隐藏状态预测算法。
•通路丰度的推断现在依赖于MinPath,这使得这些预测更加严格。
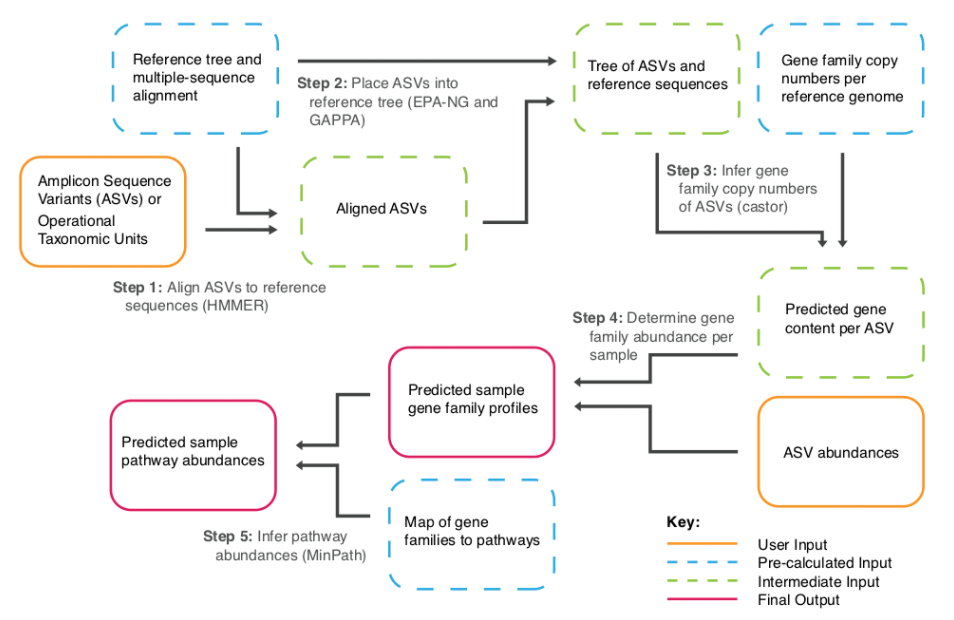
Picrust2集成了现有的开放源代码工具,以预测环境采样的16S rRNA基因序列的基因组。PICRUSt2中的系统发生放置基于三个工具的输出:HMMER、EPA-ng、GAPPA,以将研究序列(即OTU和ASV)放置到参考树中。
使用的方法更快的R包castor用于核心隐藏状态预测功能。然后生成元基因组图谱,可以通过贡献序列对其进行分层。最后,基于元基因组图谱预测途径的丰度。
默认情况下,输出文件包括对酶分类(EC)编号,KEGG直系同源物(KO)和MetaCyc途径丰度的预测。
谷禾报告中针对性的添加了碳水化合物活性酶数据库(CAZy)、肠道代谢模块(GMM)和肠脑模块(GBM)。GMM和GBM是从KEGG的KO映射出来的。
EC_metagenome_out/ 细菌群落酶(EC)功能的丰度预测结果
ECpred_metagenome_unstrat_descr.tsv 为包含基因名称的丰度表,结构同上

KO_metagenome_out/ KO(KEGG Orthology)功能基因注释结果
KOpred_metagenome_unstrat_descr.tsv 为包含基因名称的丰度表,第一列是以KO ID名称代表特定的功能基因,第二列是功能基因的描述。
丰度计算由16S rRNA拷贝数标准化后的OTU丰度表推断得到。

KEGGpathways_out/ KEGG代谢通路注释结果
上述预测得到的以KO ID为名称的KO功能,实则代表了特定的功能基因,将这些功能基因映射到具体的KEGG代谢途径(KEGG pathway)中,并统计各途径在各样本中的丰度,获得该表。
KEGGpath_abun_unstrat_descr.tsv为包含代谢通路的丰度表

pathways_out/ 代谢通路pathway添加注释,基于METACYC数据库的注释结果
METACYCpath_abun_unstrat_descr.tsv为包含代谢通路的丰度表

GMMmodelout/ 菌群代谢产物模块预测结果,modules.tsv为丰度表

GBMmodelout/ 菌群神经递质代谢产物模块预测结果,modules.tsv为丰度表

CAZYout/ 菌群碳水化合物代谢CAZy预测结果,pred_metagenome_unstrat.tsv为丰度表

COG_metagenome_out/ COG预测结果
COGpred_metagenome_unstrat_descr.tsv 为丰度表

PFAM_metagenome_out/ PFAM功能域模块预测结果
pred_metagenome_unstrat.tsv为丰度表
TIGRFAM_metagenome_out/ TIGRFAM功能域模块预测结果
pred_metagenome_unstrat.tsv为丰度表
out.tre 所有OTU代表序列构建的系统发育树文件
Intermediate/ 一些中间文件
KEGG,全称Kyoto Encyclopedia of Genes and Genomes,是一个从分子水平信息,特别是基因组测序和其他高通量实验技术产生的大规模分子数据库,以了解细胞、有机体和生态系统等生物系统的高级功能和效用的数据库资源。
MetaCyc,全称Metabolic Pathways From all Domains of Life,一个庞大而全面的数据库,只包含非冗余且通过实验手段阐明过的代谢通路。里有参与初级和次级代谢的各种通路以及相关代谢物,生物化学反应,酶和基因等信息,通过存储具有代表性的实验验证的代谢通路,来对所有生命的代谢过程进行分类。
CAZy, 全称为Carbohydrate-Active enZYmes Database,碳水化合物酶相关的专业数据库,内容包括能催化碳水化合物降解、修饰、以及生物合成的相关酶系家族。
其包含五个主要分类:糖苷水解酶(Glycoside Hydrolases, GHs)、糖基转移酶(GlycosylTransferases, GTs)、多糖裂解酶(Polysaccharide Lyases, PLs)、糖酯酶(Carbohydrate Esterases, CEs)和氧化还原酶(Auxiliary Activities, AAs)。
此外,还包含与碳水化合物结合结构域(Carbohydrate-Binding Modules, CBMs)。五大分类和一个结构域下,都分别建立了多个Family。
GHs:糖苷键的水解和/或重排
GTs:糖苷键的形成
PLs:糖苷键的非水解裂解
CEs:水解碳水化合物的酯类
AAs:与 CAZymes 协同作用的氧化还原酶
CBMs:与碳水化合物结合
★ METACYC与KEGG都可以用来微生物的代谢通路预测,那么两者有什么区别呢?
MetaCyc的代谢物信息相较于KEGG提供内容更多,除了基础的物质信息以外,还包括物质的化学性质(如:油水分配系数、拓扑极性表面积、标准吉布斯自由能等)。
KEGG在通路方面的检索方式比MetaCyc更简单一些,通过通路名称或一个代谢物即可检索到相关的通路,而MetaCyc除了通路名称外,还需要提供通路中包含的4个底物才能检索到对应的通路;另外,在通路的完整度上,KEGG中更加注重的是在所有物种中的通路汇总到一张图上,而MetaCyc更加注重的是不同物种中通路的差异化。
KEGG的通路会覆盖的更全一些,而MetaCyc相对会少一些,但是MetaCyc可以补充部分KEGG通路上不全的部分,因此KEGG与MetaCyc可以相互补充,达到相得益彰的效果。
// 提示
想要查询不同功能的细节,解释生物学现象等,可以从数据库官网上查询,例如:
KEGG通路层级汇总:
Picrust2输出KEGG只有KO,KO层级通常有7、8千的功能条目。缺少PICRUSt1中分类合并为一级、二级、三级的3级通路,这里我们重新整理KEGG的层级数据并实现此功能,合并后仅剩500多个条目,方便比较和描述。
生成的分类层级文件
Picrust2/KEGG.PathwayL1.raw.txt
Picrust2/KEGG.PathwayL2.raw.txt
Picrust2/KEGG.Pathway.raw.txt
KEGG官网页面上给出了所有pathway的名字及其隶属关系,分成三个级别。
一级分类:共7个,分别是Metabolism(代谢)、Genetic Information Processing(遗传信息处理)、Environmental Information Processing(环境信息处理)、Cellular Processes(细胞过程)、Organismal Systems(有机系统)、Human Diseases(人类疾病)和Drug Development(药物开发)。

二级分类:在一级分类下面的分类,例如一级分类Cellular Processes下面包括5个二级分类:Transport and catabolism、Cell growth and death、Cellular community – eukaryotes、Cellular community – eukaryotes和Cell motility。
三级分类:二级分类下面的分类,例如二级分类Cell motility下面包括3个三级分类:Bacterial chemotaxis、Flagellar assembly和Regulation of actin cytoskeleton。

富集分析的结果一般都是三级分类,因此使用二级分类对三级分类进行汇总,可以快速找到相关的通路。例如Cell growth and death(细胞生长与死亡)相关通路。
根据3级层级分类通路数据,做KEGG分类层级图
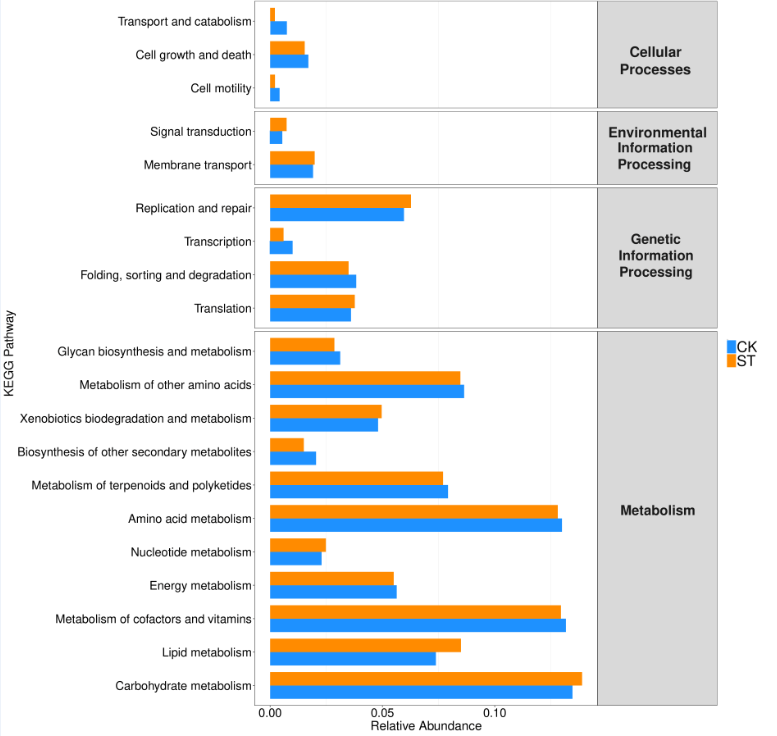
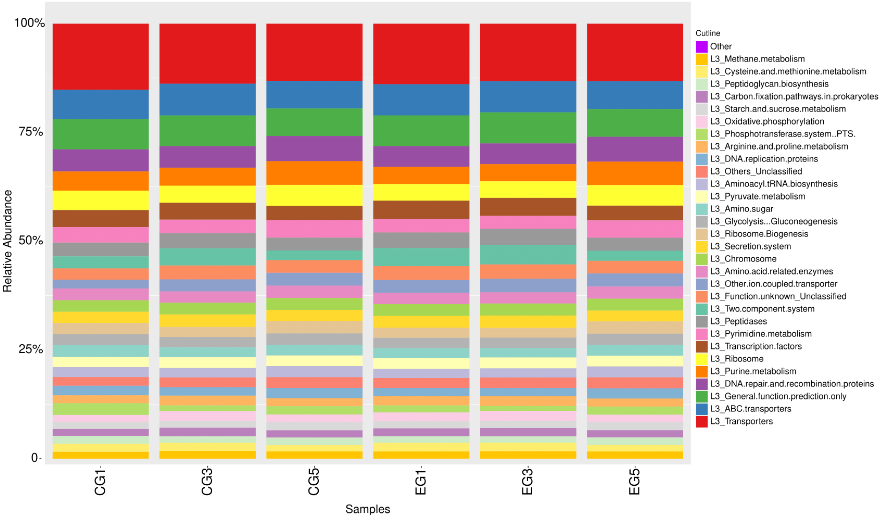
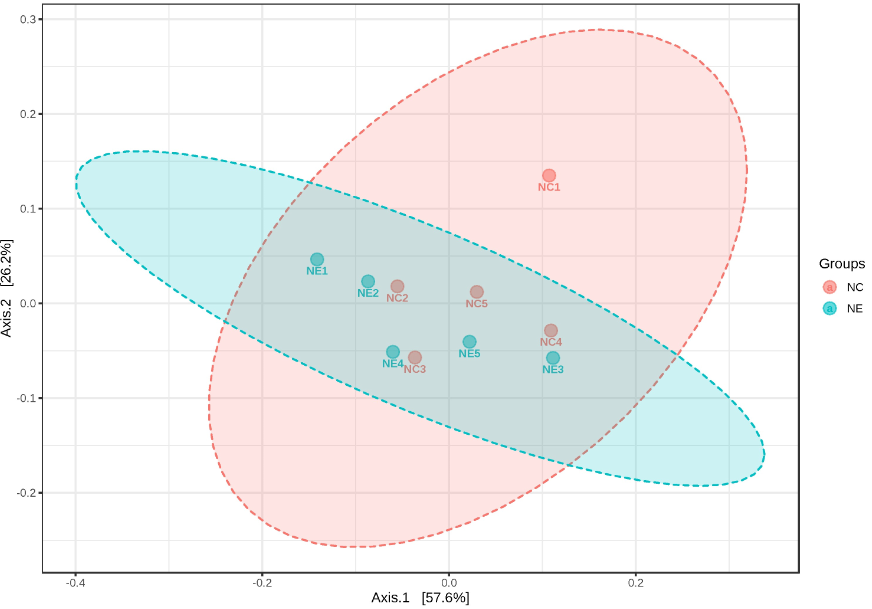
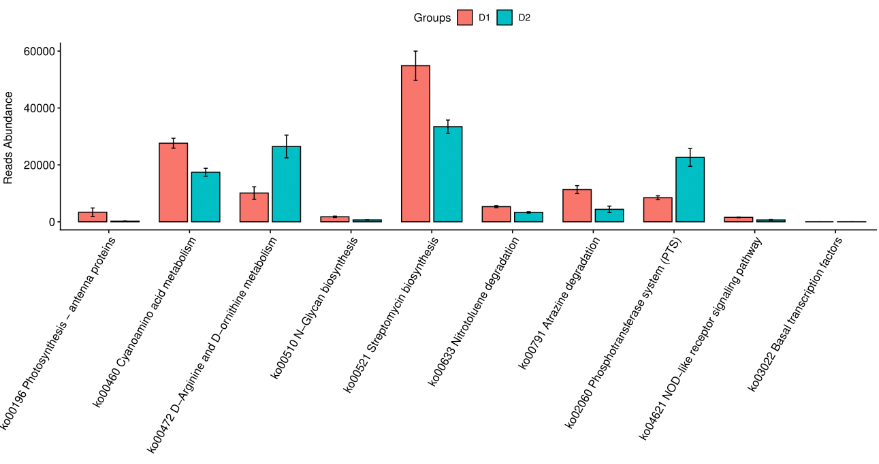
预测信息可视化
得到的上述菌群功能丰度表之后,可以参考OTU丰度表做类似可视化分析。例如相对丰度构成图,主成分分析PCA图,功能差异图等。